熟悉金庸老先生《倚天屠龙记》的都知道,张无忌在最落魄的时候变成了曾阿牛。而让曾阿牛又变回张无忌的人生际遇就是,他先是学会了“九阳神功”,又在一生死敌成昆的催逼下打通了任督二脉,后面又学会了明教的护教神功“乾坤大挪移”。
出生靠父母,成事靠修行。这才是英雄少年的成功模式。不过,更重要的一个启发是这里——在李连杰版《倚天屠龙记》里,小昭照着波斯文对张无忌说了一番话:
普通习武者要想学会乾坤大挪移,需要至少30年;但如果已经打通任督二脉,则只需最多3个时辰。

30年太长,英雄少年们等不起,自动驾驶产业也等不起。3个时辰太短,武侠玄幻当然可以,但自动驾驶产业却没法这般速成。
不过,自动驾驶技术在最近几年的快速进展,正是得益于深度学习算法在自动驾驶领域的应用,特别是Transformer这一深度网络模型,就像打通自动驾驶的“任督二脉”一样,对于自动驾驶技术的成熟,在未来的3-5年当中,将发挥着举足轻重的作用。
三十年太久,只争朝夕:将Transformer引入自动驾驶
经过数年的发展,如今自动驾驶技术已经拥有了颇为瞩目的成绩,基于L2级的高速域辅助驾驶产品已经实现商业化落地,而城市域辅助驾驶产品也将在年内实现首批规模化落地,距离L3级自动驾驶几乎只差“临门一脚”。
话虽如此,但对自动驾驶来说却并不简单,就像张无忌在面对眼前的乾坤大挪移秘籍时,如果没有打开任督二脉,哪里有时间为它训练30年呢?
所以这个时候,横扫NLP与CV领域的Transformer深度网络模型,便被科技的浪潮以“任督二脉打开者”的身份,推到了自动驾驶产业的前台。
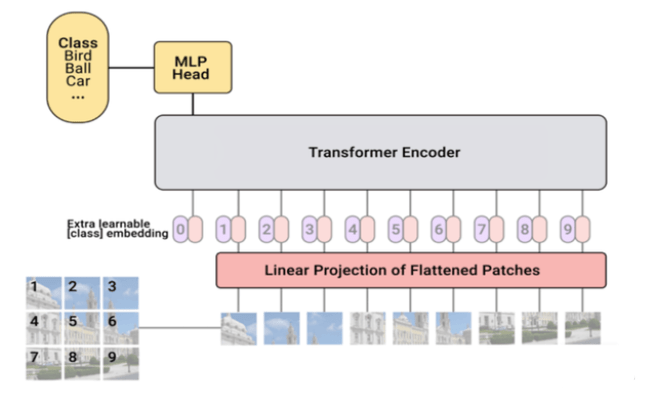
在Transformer到来以前,包括自动驾驶在内的整个人工智能领域都生活在一片“天下苦秦久矣”的环境中,算法模型制约着整个产业的进步。
具体来看,早期的算法模型生产就如同手工作坊,纯手工的生产效率和生产成本都非常原始,很难满足生产大量算法模型的需求。
另一方面,纯手工制作算法模型的通用性也很低,因为人工制作的精度不如机器,可以说每一个算法模型都是“世上仅此一件”的孤品。总之,就是算法模型间不具备通用性,非常影响效率。
事实上,在人工智能发展的早期阶段,由于算力性能和应用场景还不成熟,人工智能的发展规模并没有达到当时算法模型的设计上限,所以受关注程度并不算高。
但如今,以自动驾驶为代表,人工智能产业的发展速度早已今非昔比,不仅芯片算力在各大人工智能厂商的入局下进入了军备竞赛,云端大算力中心也成为了一种趋势。

有了大算力平台的加持,算法模型就能充分发挥其功能,实现规模效应。但如果此时的算法模型还处在“纯手工时代”,那必然会极大浪费平台算力,并且拖累迭代效率,有关边际成本居高不下的问题也没有得到最终解决。
所以,大模型之于人工智能,就成为了一种必然的选择。人工智能行业可以使用海量数据对大模型进行预训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
这样做的好处是什么呢?就相当于你手中所有电子设备的接口都变成了统一标准,不仅可以用手机充电器直接给电脑充电,也可以用电脑U盘直接给手机传文件。
在算法模型需要在各领域落地时,人工智能可以直接从预训练过的大模型中蒸馏出小模型,这些小模型能够继承大模型的所有优点,并且彼此之间“心有灵犀”,在具备更高通用性的同时,对所需场景的数据量也相对更少。
由此可见,大模型+小模型是人工智能产业提升效率、降低边际成本的一大关键,而得益于强大的序列建模能力与全局信息感知能力,Transformer从一众大模型中脱颖而出,成为了自动驾驶领域的首选。
一方面,Transformer是一种“遇强则强”的深度网络模型,这具体表现在,其对数据量的饱和区间极高,以至于有周星驰电影《西游伏妖篇》里,猪八戒遇上蜘蛛精时“你越抵抗,我越兴奋”的效果。
有研究发现,当预训练数据集增大到1亿张图像时,训练后的Transformer性能开始超过CNN,而当数据集达到10亿张时,两者的性能差距变得更大了。

从自动驾驶第一性原理我们可知,数据是驱动自动驾驶迭代的核心,这意味着Transformer正好能够与特斯拉、毫末智行的规模化量产能力形成匹配,形成一套自动驾驶高速迭代的闭环。
另一方面,Transformer 对于图像中的扰动以及遮挡等情况下,具备很强的鲁棒性和泛化性,这能够提升自动驾驶的稳定性,避免特殊场景对使用体验的影响。
具体来看,在自动驾驶感知识别中,经常会因雨雪天气、视觉遮挡以及重叠等原因,CNN模型会出现错误的判断,而Transformer针对这类问题的处理则具有更好的性能。
自动驾驶企业特斯拉与毫末智行首先宣布了对Transformer的应用。在2021 TESLA AI DAY上,特斯拉AI高级总监Andrej Karpathy宣布,将引入Transformer进行大规模的无监督学习。
同年年底,毫末智行CEO顾维灏在2021 HAOMO AI DAY上宣布,Transformer将作为毫末智行数据智能体系MANA的一大“撒手锏”。
在Transformer的加持下,特斯拉已经实现了FSD对高速域与城市域辅助驾驶功能的覆盖,而毫末智行也将推出中国第一款基于“重感知”技术路线、具备大规模量产能力的城市域辅助驾驶产品城市NOH。
Transformer为特斯拉与毫末智行打开了自动驾驶的任督二脉,令其获得了快速领悟乾坤大挪移秘籍的能力,但运用Transformer也并非像点穴那样简单。
打开通路:量产与数据让自动驾驶加速狂奔
前面我们提到,Transformer可以充分发挥大数据的价值,而想要让Transformer全力输出,就需要海量数据的支持。
这一点恰好和自动驾驶企业理想中的商业模式吻合。在后者的构想中,搭载自动驾驶产品的车辆会借助规模化量产实现大规模落地,而有越多的车辆上路,就会有越多的数据获取。
早在2020年初,特斯拉辅助驾驶系统的用户累计行驶里程就已经超过了48亿公里,同时搭载有FSD的量产车也已超过60万台;2022年,伴随着柏林与德克萨斯两座新工厂的上线,特斯拉的年产能将轻松突破百万台。
作为自主品牌的“上三家”,长城汽车同样具备百万级的汽车年产能实力,而也正得益于此,搭载毫末智行辅助驾驶系统的用户行驶里程也在近期快速突破了1000万公里,未来这一数据还将依托于规模化量产能力,实现指数级增长。
在引入Transformer以前,自动驾驶一直处在“低着头走路”的状态,这种模式或许能把脚下的路看得很清晰,但直到撞墙以前,你根本不知道你面前会出现什么样的状况。
而在引入Transformer以后,自动驾驶终于可以“抬起头走路”了,由此带来的改变是相当明显的,泛化性与鲁棒性有了明显提升。

Transformer对特斯拉带来的提升是非常明显的。由于是纯视觉方案,特斯拉本就对“眼观八方”有着更高的要求,而Transformer就可以基于全局视野,预训练出一些能够对物体深度信息进行准确感知和预测的算法模型,逐步实现2D图像-3D空间-4D空间的搭建,让世界看起来更真实。
在规控方面,特斯拉则利用车主数据,同样从Transformer预训练多套算法模型,这些算法模型可以模拟各种复杂场景下驾驶者的博弈策略,保证自动驾驶的安全性、舒适性与高效性。
毫末智行对Transformer的应用相对更复杂些,因为它不止有“眼睛”,还有“耳朵”。毫末智行HPilot 3.0的感知硬件包括了摄像头和激光雷达,这意味着其不仅要像特斯拉一样重建视觉感知的世界,还要将激光雷达的数据也融入其中。
对此,毫末智行的第一步就相当有挑战性,其选择将视觉与雷达感知数据进行前融合,这与业界普遍采用后融合的方式截然相反。
前融合可以在空间时间同步的前提下,只用一个算法模型将所有传感器数据融合,由此得到的数据包含有多维综合信息。就像在红白机时代,买99张单款游戏盘和买1张99 in 1游戏盘的区别一样,显然后者更好,因为它省去了重复购买和切换游戏盘的时间。
前融合在高速域辅助驾驶产品中相对容易做到,但到了城市域却很难行得通,因为城市域辅助驾驶系统的感知硬件种类、数量和布置位置更多,想要融合这些感知数据,对融合算法与算力的要求极高。

但在360T自动驾驶计算平台“小魔盒3.0”的支持下,毫末智行可以使用Transformer轻松补齐前融合在算法领域的遗憾。
通过预训练Transformer得到的多模态算法模型,毫末智行可以把摄像头和激光雷达获取的感知数据融合映射为一套3D空间,然后加入时序的特征,并使用循环神经网络RNN和光流SLAM进行时空融合,获得一套具备时序的4D空间。
使用前融合的效果是立竿见影的,毫末智行可以充分利用多传感器带来的冗余感知优势,而在前融合之后,毫末还会使用前融合数据再进行一次“后融合”,这一过程相当于是二次检查,由此得到的感知数据自然也更精确真实。
除了对感知的“是什么”有了更精确的判断,Transformer还实现了对红绿灯识别、红绿灯与车道绑路、车道线拓扑等“怎么走”难点问题的有效解决,这些也都归功于Transformer,由此毫末自动驾驶实现了“抬起头走路”,从前低着头走路遇到的问题自然也不再是问题了。
认知方面,为了让自动驾驶的表现更像人,毫末智行同样通过预训练Transformer得到多模态算法模型,并使用混合数据进行训练。
具体来看,现阶段辅助驾驶产品的痛点在于,“虽然技术上实现了,但使用体验并不好”,也就是产品的规控策略太机械,完全不像人类驾驶一样舒适与高效。
而通过对Transformer的运用,毫末智行则得以从海量真实数据中筛选值得训练的优质数据,再使用这些优质数据训练算法模型;此外,毫末智行也可以在仿真系统中对模仿人类驾驶,由此得出仿真数据,通过与真实的优质数据进行混合与拉齐,进一步提升算法模型的泛化性与鲁棒性。
Transformer对特斯拉与毫末智行带来的提升是立竿见影的。当前,特斯拉FSD已经实现了对高速域与城市域辅助驾驶功能的覆盖,甚至在海外用户的测试下,实现了在美国东西海岸之间跨越600公里的城市-快速路-高速无接管驾驶。

毫末智行则以数据智能体系MANA为依托,并以“小魔盒3.0”为算力支撑,推出了国内首款基于“重感知”技术路线的城市域辅助驾驶产品城市NOH;此外,由于摆脱了对高精地图的依赖,城市NOH也是国内首款具备大规模量产能力的城市域辅助驾驶产品。
打通“任督二脉”之后,高手对决正式开场
作为深度神经网络模型,Transformer对自动驾驶的影响是巨大的,通过大规模应用Transformer,自动驾驶企业不仅能够实现自动驾驶技术迭代的飞跃,也能在这一过程中实现“降本增效”,更是能够为未来产品的规模化量产奠定基础,可以说是一举多得,完全可以称得上是“打开了任督二脉”。
除特斯拉与毫末智行外,其他自动驾驶企业也在技术迭代过程中发现了Transformer的重要性,并开始将这一技术引入自动驾驶中,诸如百度、华为等也陆续开起了对Transformer的研究,由此我们得以见证2022年自动驾驶下半场竞争中“百家争鸣”的热闹局面。
热闹归热闹,属于自动驾驶企业发展的窗口期正在逐渐缩小,自动驾驶企业也需尽快将Transformer吃透,以防止在下半场竞争中落败;同样,由L2到L3的质变也即将迎来最终阶段,能否彻底参透自动驾驶这本“乾坤大挪移”,对已经打通了任督二脉的自动驾驶企业来说,真正精彩卓绝的高手对决,才正式鸣锣开场。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com



