今日,由中国信息通信研究院、浙江省经济和信息化厅、杭州市人民政府、中国人工智能产业发展联盟主办的「杭州通用人工智能发展论坛」在未来科技城圆满落幕,中国工程院院士潘云鹤、工信部科技司副司长任爱光、杭州市副市长孙旭东、浙江省经信厅总工程师李永伟、中国信通院党委副书记王晓丽出席论坛并致辞。

大会邀请到了来自中央和国家机关、地方政府、知名企业、研究机构的近1000位各界代表参会,共同探讨大模型应用现状,展望发展趋势。作为专注于对话式AI技术应用的浙江省级专精特新企业,百应科技受邀参会作主题报告,并获评《2023大模型研发应用和工具平台优秀案例》奖、《2023生成式人工智能技术和应用优秀案例》奖以及《大规模预训练模型技术和应用评估方法》参编证书。
在「大模型技术如何赋能对话式AI应用」的主题演讲中,百应科技技术VP吴凯对大模型技术对行业带来的变化以及大模型技术如何深入业务场景解决实际问题进行了深度剖析,并向各界参会代表展示了百应在AI大模型技术领域的最新研究成果与落地实践。
他表示:“大模型加速了通用人工智能时代的到来。而行业级大模型以及应用,其实是一个非常好的创业的机会点。”

作为一家科技型企业,技术和产品始终是企业的生命线,这就需要持续学习、不断加强人工智能的技术深挖。因此,当一项新技术诞生并高速发展时,能否快速学习并深度应用,对于众多科技企业而言是一个“优胜劣汰”的过程。
吴凯在现场分享到:我们将持续打磨技术和产品,深度应用大模型,紧贴客户的业务场景去打通“最后一公里”,真正打造开箱即用的AI产品。“最后一公里”不仅仅是大模型应用落地的最后一公里,更是AI与人取得信任的“最后一公里”。
01
大模型加速了通用人工智能时代的到来
ChatGPT带来了一个新的技术范式,即利用一个通用的大模型,再加指令微调,然后用指令工程的方式用一个统一大模型去具体解决一个个实际的业务场景问题,同时带来的可能是更低的成本、产生比之前模型方案更大的效果。
作为深研对话式AI在智能用户运营领域创新应用的科技公司而言,百应同样在拥抱大模型方向上做了一些尝试:
1、内部赋能、深度使用:对接绝大部分大模型的公共接口,构建了内部岗位赋能的副驾驶工具箱。比如帮助程序员写代码的工具,帮助品牌同学写文章的工具,帮助设计同学画图的工具;
2、预训练+微调+能力评测:通过探索所需要的大模型能力,结合具体的对话场景,构建本地的测试集并进行评测,具体测试哪些大模型能解决我们什么样的问题,做一些经验的积累;
3、大模型重构工程体系:利用大模型的指令工程,将一些大模型的原子化能力给它解构出来,深度嵌入到我们的工程体系中。比如说意图识别、实体识别,以往都是训练一个模型来做,现在通过大模型指令的方式来实现就很方便。
02
“对话式AI”将产品、算法、工程、运营进行深度的结合
相信了解AI的朋友都知道,智能客服这个赛道竞争非常激烈,“对话式AI”的竞争其实早已不是纯粹技术的PK,而是体系化的竞争,比的是谁能将产品、算法、工程、运营在客户的业务场景中结合得更好。

大模型技术在赋能对话式AI的直接产物是百应“三维两向”产品矩阵的打造,以“数据画像、运营策略、AI内容、连接通道”为核心运营要素,构建的智能用户运营平台,其目的是助力企业构建长期用户信任关系。
用户运营的两个主流趋势是「基于数据的精细化」和「基于策略的智能化」,而对话式AI在其中的主要作用是:将AI交互的深度推进到多模态交互领域,丰富交互场景与内容。
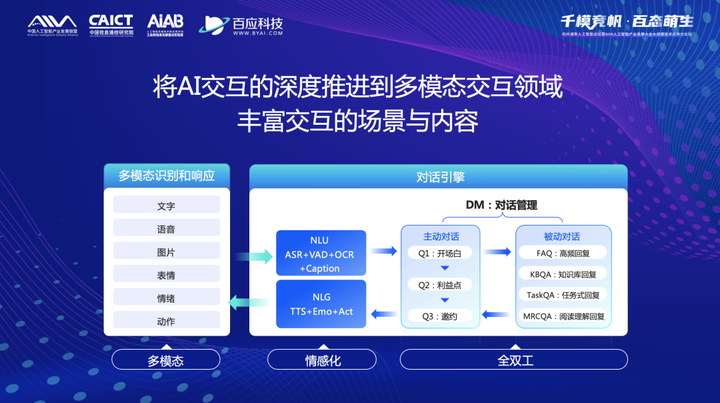
比如说,对话引擎能够结合用户标签和过往对话记录,识别出用户多模态特征的综合意图和用户特征,针对用户发出的文字、语音、表情、图片、视频以及情绪和偏好等,选择对应的模态对回复进行加工后,再进行回复;此外,除了以(被动)接待的方式解决和解答用户咨询的问题外,对话引擎还可以主动完成某些特定任务,比如私域加粉、活动通知、生日关怀等。
关于对话式AI,总结了三个主要技术特点:
1、多模态识别和响应:比如用户发的是文字我们可能会回语音、发的语音我们回图片、发图片回视频,要达到这样的效果,要求我们在系统中集成文本、语音、图片、视频等多种模态的理解和生成算法,这个其实还是很难的;
2、情感化地交流和表达:其主要逻辑是对话引擎要能识别用户的细粒度情绪,然后以合适的策略做出对应的情感表达,比如说用户不满的时候要安抚;
3、全双工连续对话:这里的主要技术难点有两个,一个是听说角色的连续切换,另一个是主动对话和被动对话的连续切换。
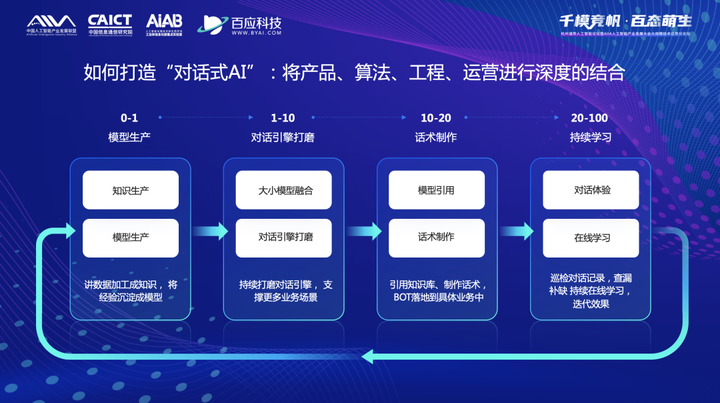
对话式AI技术有很多的产品形态,想要构建一个完整的对话式AI应用是非常复杂的。如果从生命周期的角度来拆解,至少要经历四个步骤:构建和维护底层的知识库和模型,集成多个模型打磨对话引擎,配置知识库和制作话术,上线以后的持续学习。
03
大模型显著提高了“数据处理、知识萃取、模型构建”的效率
对话式AI的底层基座是知识库和模型数据集,而怎么样快速、准确地从原始非结构化数据中萃取到知识,并且构建数据集训练出模型,一直是其中的重点,同时也是难点。
为了解决这个问题,很多公司都会尝试提供一些工具(比如标注系统、模型管理系统、自学习平台)、然后组建团队进行系统性的培训,试图批量化地复制最佳实践;
然而还是经常会碰到数据不一致、效率不高、管理困难等等问题,究其原因,主要是以前的小模型技术不成熟,具体表现在:
1、每一个小问题都需要一个小模型,比如分词一个模型、意图一个模型、实体一个模型;
2、每个小模型都需要人工标注许多数据,需要才能训练出来;
3、小模型是基于小数据的耦合,缺乏深度语义理解,缺乏上下文关联理解。
基于这些问题导致其中很多环节主要靠人,而人工智能也被戏称为“只有人工没有智能。”
而在经过“大模型时代”的洗礼后,最终却有可能变成以AI为主导,“人”只需要在关键环节上做简单的对错选择,进而大大提高数据处理、知识萃取、模型构建的效率和效果。
吴凯在会上分享了一个实际案例:百应与济南市中公安局联合打造的AI警察朋友“卫民小微”。在解决实际问题上,它可以负责当地许多业务的线上咨询和办理。

比如说「落户办理」,它的政策依据是一个十几页的word文档,而这个文档是经常更新的,并且每个地方都不一样。如果按照以前的方式,通常要半个月左右才能支持一个业务的上线,而且每次业务的更新都需要重新构建和维护知识库和模型,关键还无法通用,只能一个客户一套模型。
而现在有了大模型以后,如何来解决这个问题,实现降本增效呢?
首先是大模型对文档进行加工处理成本地知识库,里面的细节问题非常非常多,比如不同格式的预处理,比如标题、关键词、段落、表格的处理,比如切片、问答对话、向量检索、指令集等;整个pipeline方案的效果非常依赖于细节是否做得足够好。
然后是基于本地知识库的问答,其原理是基于匹配到的具体政策依据进行答复,而不是创作一个答案。
相比于以前靠人工为主的知识库构建和答案配置,其自动化程度得到了显著提高,整个问答流程可以保存完整的决策链路,这更类似于人的思维方式,可以基于人工反馈进行持续迭代优化大模型,极大地降低了“人”的参与程度和人力成本,同时在“数据处理、知识萃取、模型构建”方面的效率得到大幅提升。
04
大模型让对话式AI从预设模式逐渐转为生成式
对话式AI的另一个重点环节,即“话术制作”,主要包括知识库配置、话术文案、策略编排等。
如果说之前,按照行业惯例,大家做得更多的是预设式 AI,全程需要人的高度参与,包括策略布局、流程部署、话术设计等。在外呼过程中,根据与用户的沟通和交互,去识别用户意图,并进一步引导到预设的分支流程话术中。
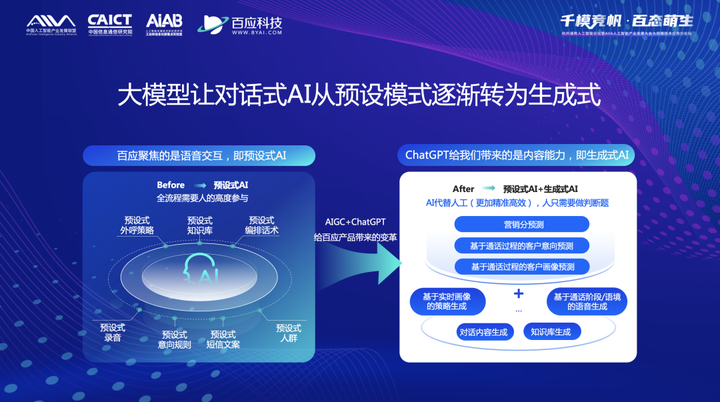
而大模型让整个“对话式AI的模式”从之前的预设模式逐渐转为今天的生成模式。包括视频内容生成、文本话术生成,甚至是运营策略的生成。它能大幅度提升智能外呼业务的效率和有效性,提升人机交互体验。
大模型技术将赋能 AI 对话效果全面升级。百应目前已经应用实践的能力,比如:话术文案的生成,能够快速实现话术内容也好、知识库也好、兜底文案,比如开场白、利益点、邀约都是如此;另外一个是视频内容的生成,即把一段文字实时驱动一个数字虚拟人,这里面的主要技术是口唇驱动、表情驱动和动作驱动,通过这个技术,可以随时驱动一些数字人来进行动态的交互,也可以渲染成视频在私域内传播,比如说大促优惠介绍、日常活动通知、产品功能介绍等。
还有运营策略的生成,我们称之为“OSA Copilot”。首先是有一个进入窗口,我们可以输入一段描述,比如说“生成一个鞋服行业的会员生日关怀策略”,它就会根据需求生成一个策略并且渲染成画布,在画布编排引擎中可以采纳、也可以重新生成,采纳以后也还可以继续追问进行完善,这个功能在运营同学没有思路的时候可以一键拓展思路,同时显著加快策略编排的效率,以前需要2天的一个策略,现在只需要1个小时左右就可以上线。
吴凯表示,在这个高速发展的时代背景下,百应将继续聚焦对话式AI领域,持续打磨技术和产品,深度应用大模型,紧贴客户的业务场景去打通“最后一公里”,真正打造开箱即用的AI产品。
相信在大模型技术的助力下,未来我们可以训练出最适配客户场景的大模型,开发出更多丰富的应用场景,致力于打造更极致更有温度的对话式AI,我们坚信科技让生活更美好!