

人工智能现在看似已经离我们很近,并且好像发展的很不错了,但其实人工智能现在的发展还面临着很多的挑战和难题。5月9日,中文通用大模型综合性评测基准 SuperCLUE 正式发布。该基准测试主要关注以下问题:中文大模型在不同任务上的表现如何?与国际代表性模型相比,中文大模型的表现达到了何种程度?中文大模型与人类表现相比如何?

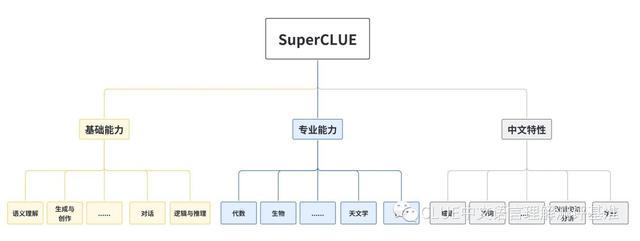
该基准测试主要关注三大问题,包括中文大模型在不同任务上的表现、相较国际代表性模型中文大模型的表现达到的程度,以及中文大模型相较人类的表现。该模型可通过多个层面,考验市面上主流的中文 GPT 大模型的能力,涵盖基础能力、专业能力、中文特性能力。
具体而言,基础能力包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力;专业能力:包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力;中文特性能力针对有中文特点的任务,包括中文成语、诗歌、文学、字形等10项多种能力。
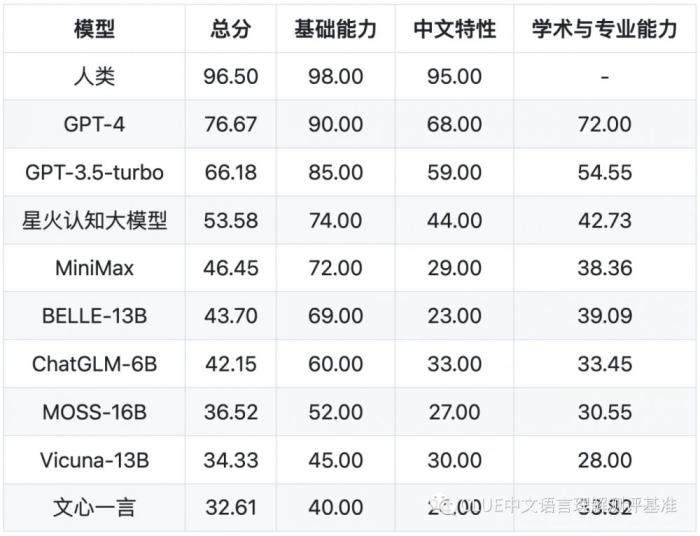
通过SuperCLUE对市面上主流的支持中文的通用大模型进行评测与排名。结果显示,GPT-4排名第一,已经非常接近人类的能力。国产大模型中,科大讯飞研发的星火认知大模型总排名第三,国内排名第一。
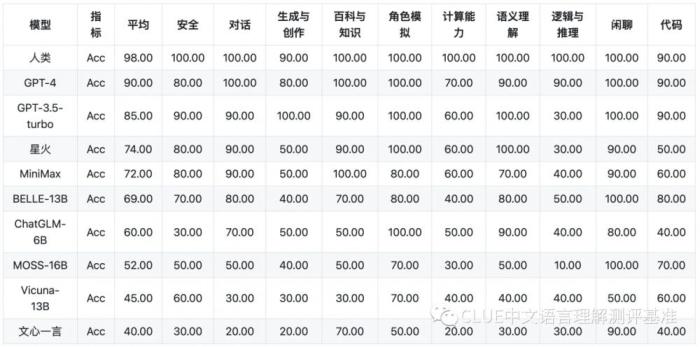
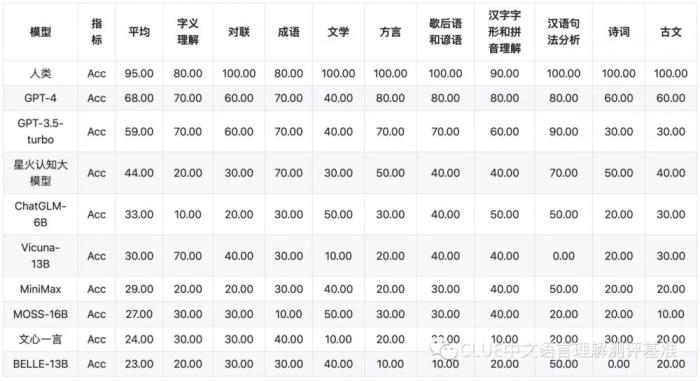
以下为该机构公布的各个子项目的具体得分,榜单显示,国内大模型中表现最好的是讯飞星火认知大模型,总分53.58分,与GPT-4相比有23分的差距,与GPT-3.5-turbo在总分上有13分的差距。值得一提的是,在语义理解方面,讯飞星火认知大模型得到100分的满分,超过GPT-4。实力不容小觑。
在笔者看来,大模型背后的核心技术是认知智能,科大讯飞作为人工智能国家队之一,多年来一直深耕认知智能领域,有能力推出自主研发的国产大模型。从科大讯飞的发展历程来看,其在2014年就提出讯飞超脑计划,目标就是让机器能理解会思考,在2022年进一步提出讯飞超脑2030计划,进一步深耕认知智能。并且承办国家语言及语言国家重点实验室、认知智能国家重点实验室以及国家新一代人工智能开发创新平台,可谓是AI国家队的代表。仅过去一年在认知智能领域就有10+项世界冠军。
该评测榜单的发布对于中国大模型的发展具有重要意义,它为评估中文通用大模型提供了重要的参考,同时也为模型的改进提供了指导。在未来,相信中国大模型将继续迎来发展,并在不断提高性能的同时,应用于更多领域,为各行各业的人们带来更好的服务。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com


