

近日,山海大模型迎来新一轮迭代升级——在性能优化方面,山海大模型不仅实现了学科和行业能力、推理能力的提升,更实现了吞吐效率、上下文窗口长度、模型参数融合方法的优化;在效果提升方面,山海大模型反事实能力大幅提高,此外,在本月的C-Eval全球大模型综合性考试评测中,山海大模型更是取得了60分以上的优异成绩,成功跻身榜单前十。
性能优化
学科和行业能力升级
山海大模型在迭代过程中一直关注不同学科和行业知识的能力升级,目前已采集包括数学、物理、化学、生物、地理,历史等多学科在内的海量教材数据作为山海大模型底座模型的训练语料,与此同时,云知声整合了其在车载、家居、金融、医疗等多个行业的数据积累,并以此为基础,在预训练阶段和指令学习阶段完成山海模型的迭代。
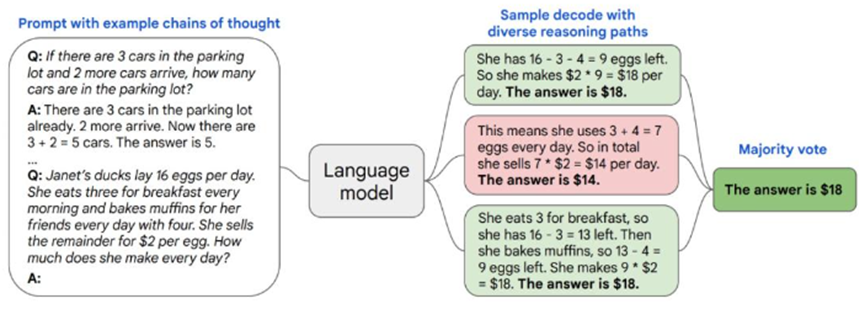
自洽性(self-consistency)方法提升推理能力
模型解码通常使用贪心(Greedy Search)或者随机(Sample)策略进行解码。山海大模型参考了谷歌提出的一种名为自洽性方法(self-consistency)的简单策略,不需要额外的人工注释、训练、辅助模型或微调,可直接用于大规模预训练模型。
尽管语言模型在一系列 NLP 任务中取得了显著的成功,但它们的推理能力往往不足,仅靠扩大模型规模不能解决这个问题。基于此,思维提示链(chain of thought prompting)提示语言模型生成一系列短句,这些短句模仿一个人在解决推理任务时可能采用的推理过程。而自洽性方法能够更好的融合思维提示链方法,使其更好的运用在解码过程中。简单来说,复杂的推理任务通常有多个能得到正确答案的推理路径,自洽性方法通过思维提示链从语言模型中采样一组不同的推理路径,然后返回其中最自洽的答案。该方法能够显著提高了山海大模型的推理准确率。
吞吐效率达到理论上限65%
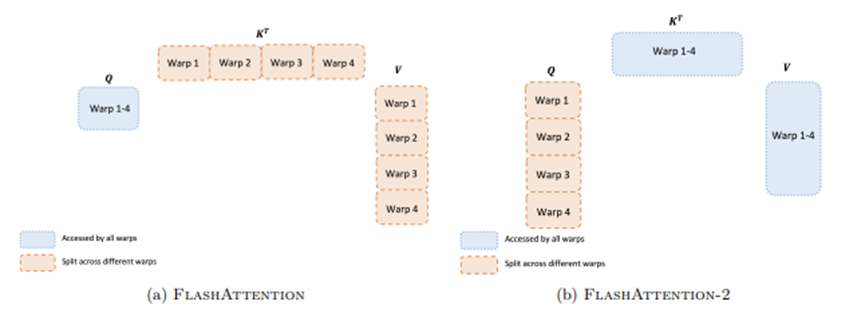
处理长序列问题一直是扩展Transformer的难点,因为随着输入序列长度的增加,其核心注意力层的运行时间和内存使用成二次增长。云知声想要打破2K序列长度的限制,以便训练书籍、文献、多轮对话等长文本内容。当前主要通过引入FlashAttention节约内存,从而支持更长序列的模型训练。FlashAttention相较于标准Attention机制速度提升了2~4倍,内存节约了1020倍,但还是相差实际设备的最大吞吐量的理论上线还很远。为了进一步提升模型训练中计算的吞吐量,云知声自研的UniScale集成了FlashAttention-2,增强了并行性和工作分区。实验结果证明,FlashAttention-2在前向传递中实现了接近2倍的速度提升,达到了理论最大吞吐量的65%,在反向传递中达到了理论最大吞吐量的55%。这使得在每个A100 GPU上的训练速度可达到205 TFLOPs/s。
支持8K长度窗口
大型语言模型(LLM)通常会设定一个预设的上下文窗口长度,譬如,当前主流开源模型的输入不能超过2048个Token。但在很多应用场景中,如长程对话、长文档总结或长期规划等,常常会超出这个上下文窗口的限制。在这些场景下,能够处理更长上下文的LLM就显得更为重要。然而,从零开始训练这样的模型需要巨额的投入。这就引发了一个问题:我们是否可以对现有预训练LLM进行扩展,让其涵盖更长的上下文窗口呢?
参考了META的相关研究,云知声本月引入位置插值方法(Position Interpolation),将当前山海大模型的上下文窗口扩展到8K。其关键技术点是,云知声并未进行延伸处理,而是直接调低位置指标,使得最大位置指标与预训练阶段的原先上下文窗口限制相对应。

简单来说,云知声通过在相邻整数位置间插值位置编码,以容纳更多的输入标记,而非像之前那样在训练位置的外延部分进行外推,因为这有可能会导致极端的数值。云知声利用了一个特性,即位置编码可以应用于非整数位置。
与此同时,通过对比测试不同窗口长度对信息抽取能力,结果显示当长度超过10k时,模型信息抽取能力有显著的下降,云知声也将在后续工作继续迭代山海大模型的长文本理解能力。
模型参数融合(Ties-Merging)
云知声使用了一种新的模型融合方法,旨在进行指令学习后对多个模型进行合并,并解决现有方法中存在的干扰问题。该方法通过三个步骤来合并模型:修剪参数、解决符号冲突和仅合并与最终协商符号一致的参数。实验结果表明,模型参数融合方法(TIES-MERGING)在各种设置下都优于现有的合并方法。
效果提升
C-Eval超过60分
C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集,包含13948道多项选择题,涵盖数学、物理、化学、生物、历史、政治、计算机等52个不同学科和四个难度级别,是全球最具影响力的综合性考试评测集之一。
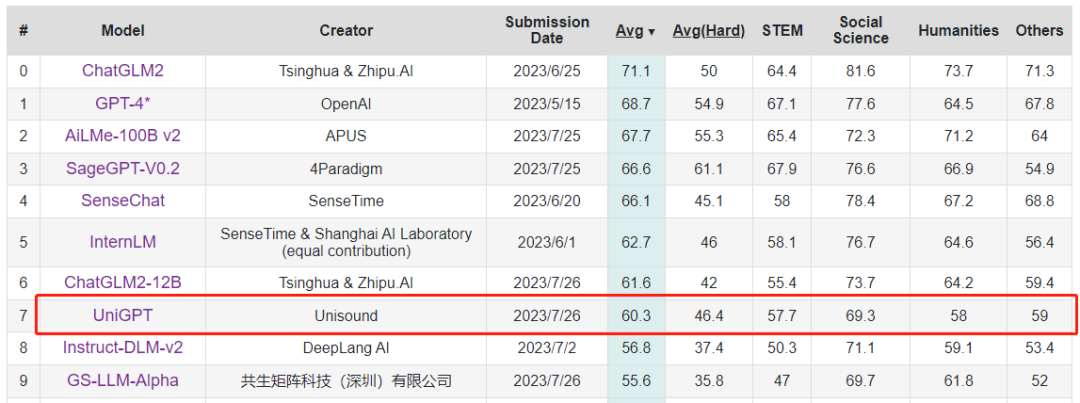
评测显示,云知声的山海大模型平均分为60.3分,跻身榜单前十,在参与评测的大模型中排名第七,充分印证了其在学科和行业领域应答能力上的突破。
反事实能力提升
用户在使用大模型时,经常会出现一种情况,就是故意设计一些复杂的陷阱问题,以测试大模型的应答能力。这些问题通常是一些对大模型来说较难理解的问题,使得其在运算过程中陷入逻辑混乱,从而引发幻觉现象。例如,用户测试大模型的问题是:猪为什么会飞?而事实上,猪根本不会飞,这种反常识的问题通常会让大模型产生混乱。
对此,山海大模型团队使用了Evol-Instruct技术,生成了大量的反事实类问题。这些问题上设计精巧,通过巧妙地设置陷阱,使得大模型具备应对各方面陷阱的能力。同时,大模型还使用了人类反馈的强化学习算法,这是一种在模型训练过程中,根据人类反馈和指导进行学习的方法。这种方式,让大模型能够更好地理解人类的意图,从而在回答问题时,更加符合人类的逻辑思维。经过了大量的训练和优化,山海大模型在处理这类陷阱问题时,表现出了更好的应对能力,结果展示如下:

从5月24日正式发布以来,山海大模型始终保持加速演进,在一次次迭代升级下,持续构建长期竞争力与创新基石,致力为大模型的场景落地带来范式革新。
目前,云知声正依托山海大模型技术能力的加速迭代,逐步深入到智慧医疗、智慧教育、知识管理、智慧营销、智能客服、智慧车载、智慧轨交等具体场景,不断释放AGI的更多可能。
作为一个具备语言生成、语言理解、知识问答、逻辑推理等十项核心能力的通用大模型,山海大模型通用能力表现颇佳的同时,在专业领域更是表现出众。自5月24日发布以来,山海大模型通过语料的不断迭代升级,专业能力持续突破。其中,其医疗能力在上个月的MedQA任务上提升到了87.1%,超越Med-PaLM 2,临床执业医师资格考试提升至523(总分600分),超过了99%的考生水平。凭借山海在医疗领域的技术实力与场景落地能力,云知声更是接连获得北京市首批人工智能行业大模型应用案例、2023北京人工智能行业赋能典型案例等荣誉奖项,表现出不俗的专业实力。
每一次山海的技术升级,都标志着云知声在推动场景智慧化道路的重大进步。让我们期待并共同见证,山海大模型的下一个飞跃。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com


