

近日,未来网络创新科技成果发布仪式在第八届未来网络大会上同期举行。紫光股份旗下新华三集团算力集群核心交换机H3C S12500 AI凭借创新的DDC架构、极致的转发性能与网卡解耦能力,斩获“创新科技成果奖”殊荣,中国工程院院士刘韵洁为获奖单位颁奖。

随着全球AI话题持续升温,旺盛的市场需求进一步加速算力生态不断丰富,构建多元异构算力体系将是必由之路。算力效能的提升除了依靠更强大的处理器来增加单个设备或节点的计算能力外,更需要进行横向技术整合,使算力和联接高效协同,开放的智算网络将是打通异构算力、拉通生态的重要介质。智算网络的建设不仅是硬件设备的堆砌,面对百花齐放的算力生态,如何让网络具备开放标准与长期演进的能力,实现网络与异构算力的协同调度,解决大规模智算网络的快速部署、故障定位和精细化运维管理,是产业界普遍思考的问题。
为了最大化发挥算力资源潜能,新华三提出“算力×联接”的理念,倡导通过开放标准的联接技术与多元算力体系做最佳调配,携手产业链伙伴共同构建创新、包容的生态圈,并围绕全场景组网能力、网络性能持续提升、异构算网协同与运维管理三大方向不断探索。本次获奖的算力集群核心交换机(H3C S12500 AI)正是新华三在大规模智算组网架构方面的创新成果。

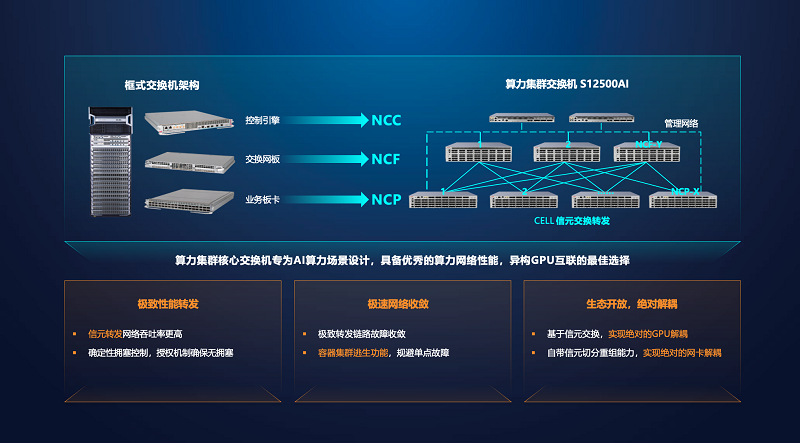
H3C S12500 AI是一款能够真正解决网络零拥塞的分布式架构产品,将传统框式设备的控制引擎、交换网板、业务板卡分别独立为盒式设备,通过高速光模块互联。DDC架构设计拥有三大创新优势:
●保留信元交换的底层机制,实现100%无阻塞能力,并且摆脱了框式设备的端口限制,最大可以支持32K GPU集群组网,同时规避了单框功耗过大的部署风险;
●拥有独立的高性能控制平面,可以实现网元失效后us级别的收敛,以及网元上线的快速即插即用,可靠性和灵活度领先业界;
●基于信元交换,任何协议的流量在进入DDC架构时都可被切成等分大小的信元,在内部多条链路上负载,完全解决了Hash极化问题,实现100%的负载分担。在流量发出时,信元又将会被重组为原始数据。信元交换无视数据协议,不会产生乱序,对GPU和网卡天然解耦。
除了创新的DDC产品外,新华三还拥有200G/400G/800G全系列高性能交换机产品,并在51.2T的交换平台上充分融合了CPO/LPO技术,以丰富的产业布局支持用户灵活组网的需求。同时,新华三还推出了《智算网络异构连通专项测试》标准,为推动国内智算生态相互协作提供了强力支撑。
智算网络性能同样也是决定算力效能的关键。无损以太网(RoCE)在成本、未来演进和生态丰富度上具备天然优势,当RoCE发展到智算网络时代,面对不同智算场景,以网络调优的方式解决Hash极化问题,降低网络拥堵风险,成为智算网络构建无损能力的关键。新华三针对异构算力场景提供FGLB路径调优算法,能够基于全局视角决策流量的转发路径,实现全网所有链路始终工作在均衡的负载水平之下,根据现网状态迅速调整路径的分配,避免拥塞发生。
除了设备自身的负载技术,新华三也将关注点放在了网络与算力间的融合调优,推出算力路径导航解决方案。基于一套UCCL(统一集合通信库)与不同的CCL对接,理解算力分配的动作和流量需求,将其转化成最优的网络配置下发到设备上,并根据网络当前的负载状况调整其算力流量的样本特征,以更好的使用网络资源。通过这种双向协同,帮助用户使用一套网络为多元异构算力提供统一的流量调度。
对于智算网络而言,如何降低网络故障对业务训练的影响、降低部署和运维复杂度是业界普遍关注的难点。新华三也在不断优化链路冗余技术,推出专用于智算网络的可靠性技术—DPSH数据平面自愈功能,实现us级的链路切换,极大减少了故障对业务的影响。在运维方面,新华三始终坚持标准化路线,采用网络标准协议,实现基于一套控制器对接上层云平台与下层纳管的网络设备。同时还为智算网络研发了多种自动化运维功能,帮助用户实现算力快速上线、平滑变更,以及算力流量的精细可视化。
面向未来,在算力爆发的时代,新华三集团将始终秉承开放共赢的理念,持续探索智算网络技术创新和应用,携手合作伙伴共同推动中国智算生态的健康发展。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:157 3889 8464 投诉邮箱:7983347 16@qq.com


