1月7日,由阿里云实时数仓Hologres和开发者社区共同举行了实时数仓年度发布会。在发布会上,来自阿里云的资深技术专家果贝从阿里的核心场景出发,深度解读了实时数仓技术发展的新趋势:一站式、在线化、敏捷化。在发布会上,Hologres产品负责人合一针对当前数仓的新趋势,重磅发布了Hologres年度重点能力,助力企业更好的建设一站式实时数仓。
本文将会从多个角度总结Hologres的重点功能,以帮助用户更加了解和使用Hologres。
源于业务创新,持续业务演进
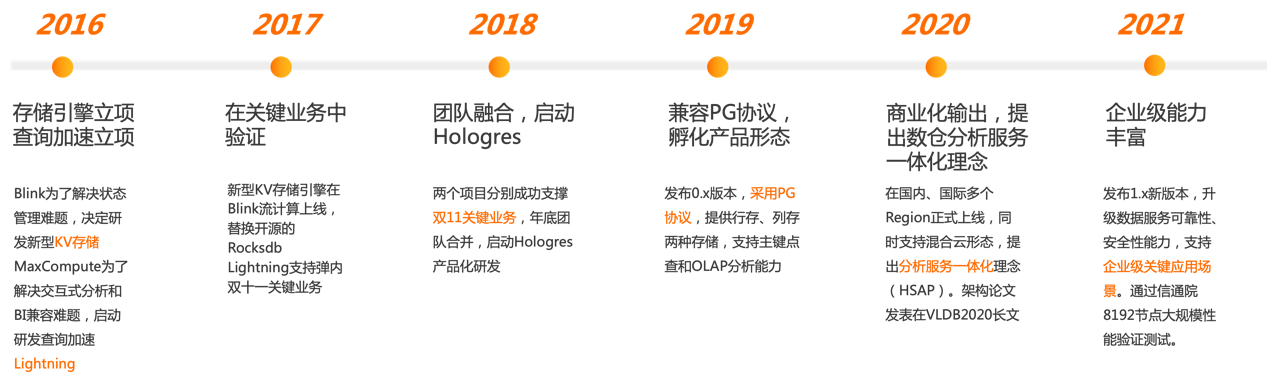
Hologres从诞生至今已经走过6年的时间,首次提出服务分析一体化(Hybrid Serving & Analytical Processing,简称HSAP)理念,逐步发展为企业级一站式数仓,不仅在阿里集团内部服务众多核心业务(如淘宝、天猫、1688、菜鸟、本地生活、达摩院等),也在持续云上服务能力输出,助力国内、国际更多企业搭建企业级实时数仓。截止目前,已经在全球13个Region同步提供服务。
全新迭代,年度重磅发布
Highlight
2021年Hologres在引擎能力上重点发力,经历了三个核心版本的迭代,下一代产品也已经在内测中,依旧保持着快速迭代的节奏。通过行列共存、高可用部署、读写分离、快速Failover等能力,显著改善了数据服务的稳定性,丰富了业务使用场景:
1、性能持续提升:每个大版本持续优化引擎性能,在优化器、查询引擎、存储引擎多个层面改进,以32core TPCH 100G测试结果为例,在1.1版本相比去年0.8版本有256%的性能提升(查询部分),提升效果显著
2、强化高并发的服务(serving)能力:行存吞吐提升100%,列存吞吐提升30%,支持行列共存,一份数据支持多个场景,列存升级AliORC格式,更高的压缩比,显著降低存储成本。
3、企业级高可用部署和企业级治理能力上重点发力,通过透出更多维度更细粒度的观测性指标,提升企业的自运维能力。

下面将会针对重点功能进行更加细粒度的介绍。
原生JSON支持
JSON是近期Hologres重点发力的领域,因为数据采集越来越灵活,数据加工也越来越敏捷,过去需要打宽拉平的JSON数据,往往保留了原始的不规范结构。因此如何处理Schemeless场景就尤为重要。
传统上,JSON作为一个数据单位,采用Schema on Read模式,提供了存储上的灵活性,但限制了分析时的效率,为了访问JSON中部分节点不得不读取整个JSON数据结构,效率非常低下,存储上也很难压缩。
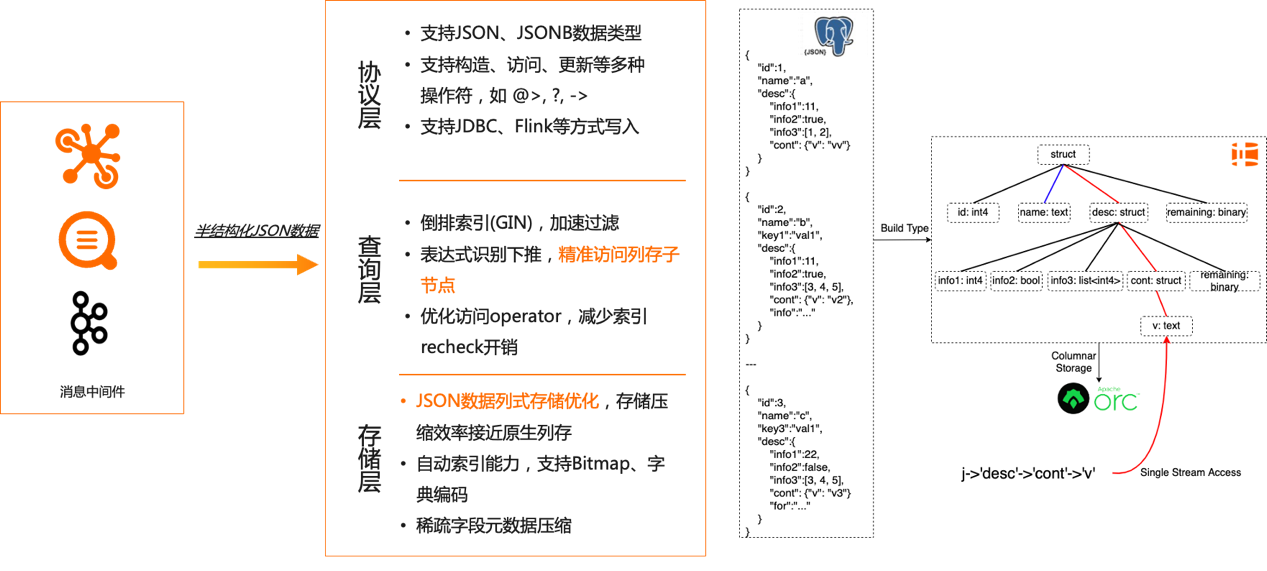
Hologres创新了JSON数据的存储方式,在底层存储上采用类似列存的存储格式,将JSON中不同的节点路径映射为虚拟的列,提供原生的列存压缩、索引能力,在查询层,自动下推JSON访问算子,极大的加速了JSON数据过滤、统计的效率。在协议层,完全兼容了PG的规范,支持了JSON、JSONB等类型,支持PG原生的各种构造、访问、更新的算子。基于这些创新的能力,JSON成为Hologres推荐的数据类型,适合于埋点日志分析的场景。详情见JSON文档。
Binlog全链路事件驱动
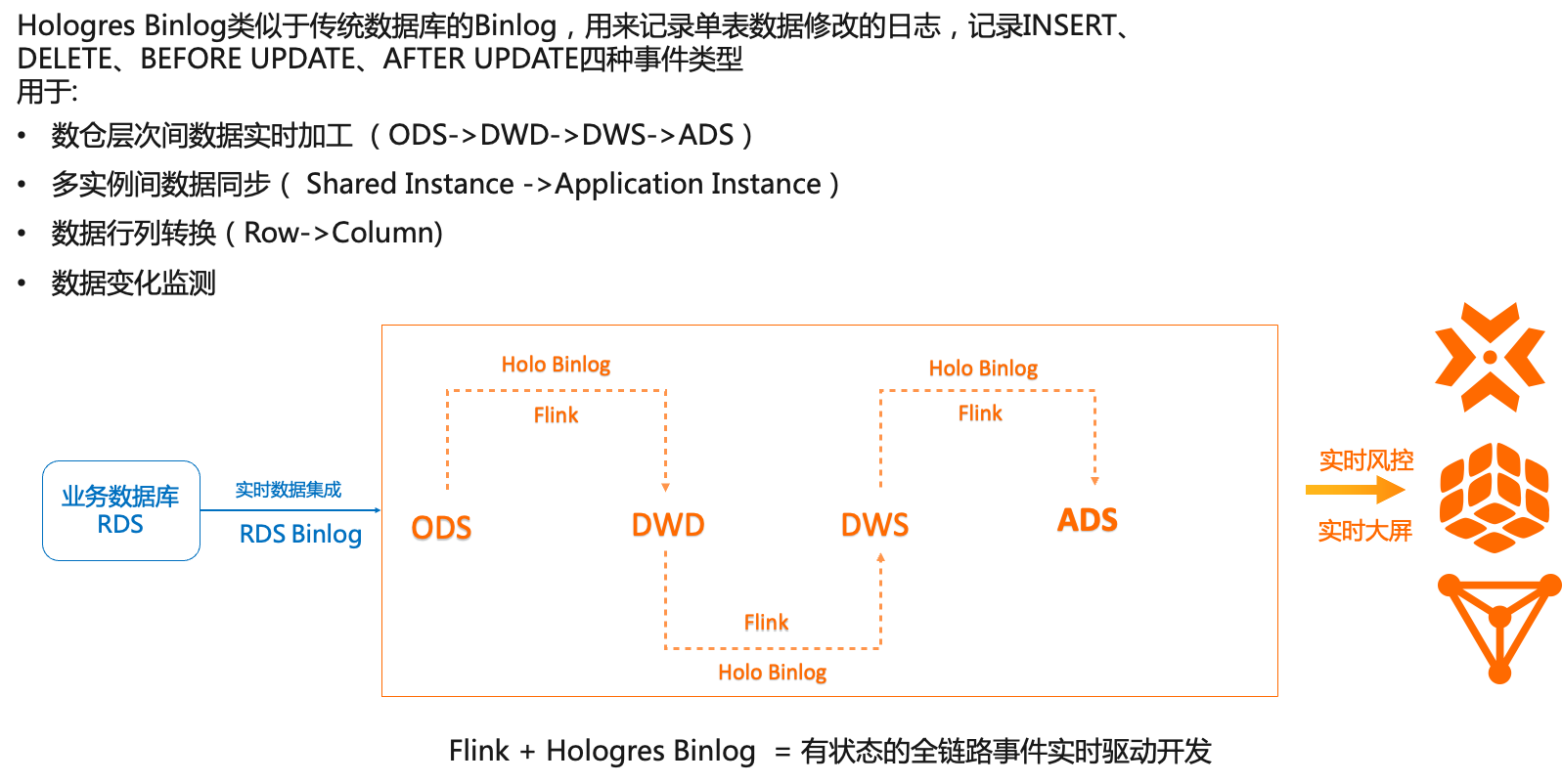
类似于传统数据库MySQL中的Binlog概念,在Hologres中,Binlog用来记录数据库中表数据的修改记录,比如Insert/Delete/Update的操作。通过Flink、JDBC消费Hologres BInlog,实现数仓层次间全链路实时开发,在分层治理的前提下,缩短数据加工端到端延迟。典型应用场景如下:
1.数据实时复制、同步场景,典型的场景就是把一张Hologres的行存表实时转化成另一张列存表,行存支持点查点写,列存支持多维分析型需求,同步的逻辑由Flink支持。这个是Hologres在V1.1版本之前的一种典型用法。在Hologres 1.1中支持了行列共存表后,可以一张表满足行存和列存两种需求,免去了额外的调度开销。
2.实现事件的全链路驱动:通过Flink消费Hologres Binlog,实现事件驱动的加工开发,完成ODS向DWD,DWD向DWS等的全实时加工作业。
3.数据变化监控:监控数据的实时变化,比如监控库存数据、敏感字段等的实时变化,触发告警。
4.数据在实例间同步:用户可以创建多个Hologres实例,分别用于公共层加工、业务域加工等职责,不同实例之间可以通过Binlog完成数据的实时同步,实现了数据的实时流动和分享。
具体使用请见文档Hologres Binlog。
实时离线一体化数仓Hologres+MaxCompute
MaxCompute是阿里云可扩展的大数据加工引擎,技术成熟、服务稳定。Hologres与MaxCompute均采用盘古存储引擎,底层技术相同。Hologres采用原生向量化查询引擎加速查询MaxCompute数据,实现对MaxCompute的查询加速能力,此种场景无需数据迁移和导入数据,高性能和全兼容的访问各种MaxCompute文件格式,为BI工具和大数据数仓之间建立起交互式分析的快速通道。Hologres新版本中,已经默认使用原生的向量引擎直读MaxCompute,减少跨引擎的RPC调用,更少的引擎间数据序列化,同一个引擎,有利于缓存的复用,性能提升30%-80%。
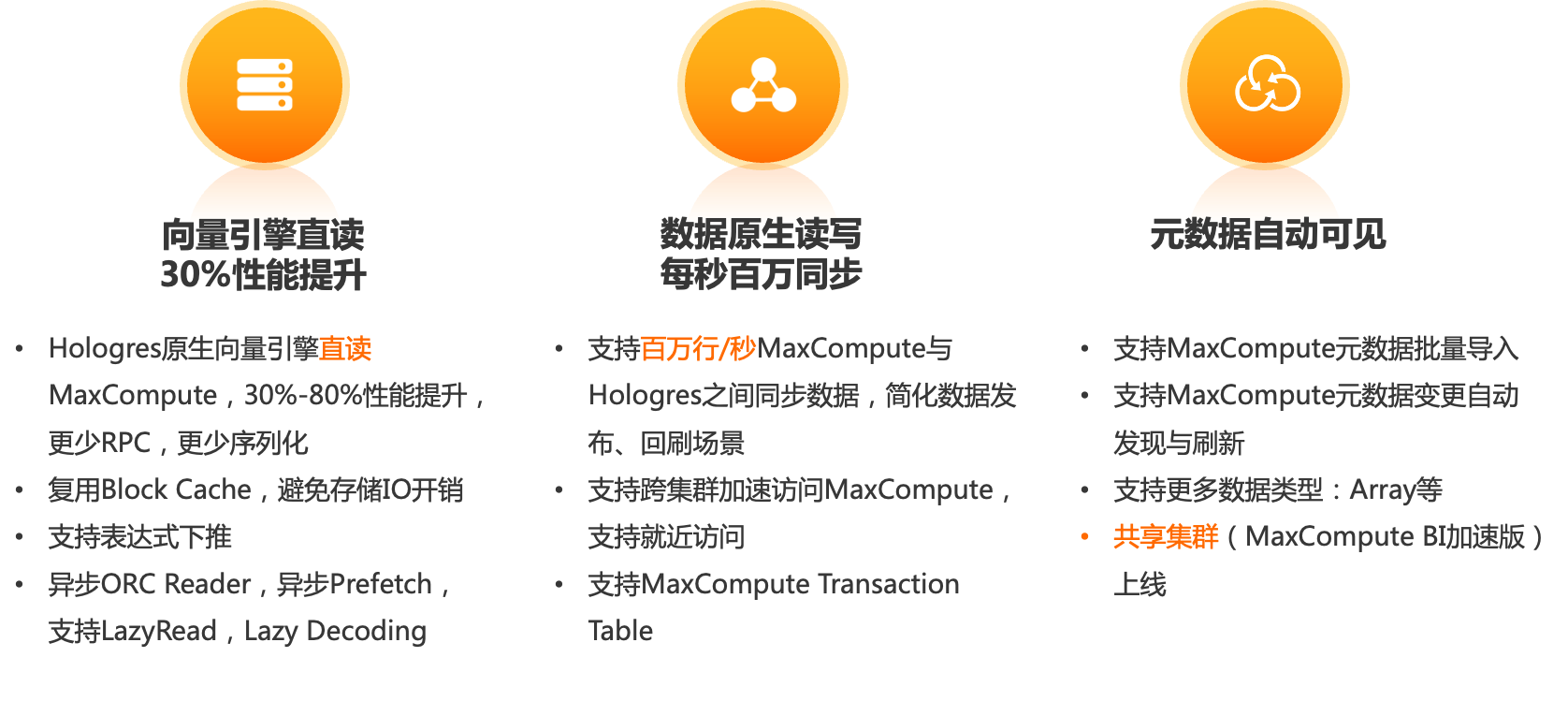
实时离线一体化方案中很重要的是数据交换的简化,甚至无需数据移动。外表查询是不需要移动数据的场景,但由于外表没有索引和SSD的优化,查询性能和并发能力低于内表场景,在性能敏感的场景下,仍然建议数据从MaxCompute同步到Hologres中,在同步操作中,同步的效率就更加重要。目前通过存储技术的创新,支持了MaxCompute与Hologres之间每秒百万行的双向同步,简化了数据开发、数据回刷的场景。
MaxCompute与Hologres元数据的打通也是一项持续的工作,早期Hologres支持了元数据的批量导入,可以把整个project的全部表一次性导入,也支持批量更新。最近Hologres支持了元数据的自动导入与刷新,当MaxCompute侧有新的表创建,或者表结构的变更,无需手动刷新,元数据可以自动同步到Hologres,体验更简便。
与此同时,为了更加友好敏捷的支持MaxCompute加速场景,Hologres提供了一种新的服务形态:共享集群。在该形态下,用户无需提前部署实例,而是采用Serverless的方式,根据查询数据的扫描量计费,这个形态仅支持MaxComputeBI加速场景,不能创建内表和索引,对于过去使用MaxCompute Lightning查询加速的用户可以平滑切换到这种共享集群中,不用重新建表,不用修改BI协议,可用连接数比Lightning更多,服务更稳定。
详情可以见文档加速查询MaxCompute和Hologres加速查询MaxCompute技术揭秘
加速数据湖探索
传统架构湖和仓还是比较割裂的,有些企业在建设数据湖时,对数据治理和数据管理相对比较困难,随着企业进程的推进,越来越多的企业开始探索湖仓一体。Hologres在今年重点优化了湖仓一体场景,支持了外表直接访问OSS数据和数据回流OSS,支持DLF集成,加速数据湖探索,助力湖仓一体建设 。详细使用请见OSS外表和DLF外表。
深化流量分析场景
流量分析是Hologres持续增加的场景,目前支持了高性能的Bitmap库RoaringBitmap,可以以常量复杂度,快速计算UV,是解决互联网级别高基数精确去重、UV计算的关键手段,广泛使用在用户画像、标签筛选等典型场景,在阿里妈妈广告场景中被深度使用。
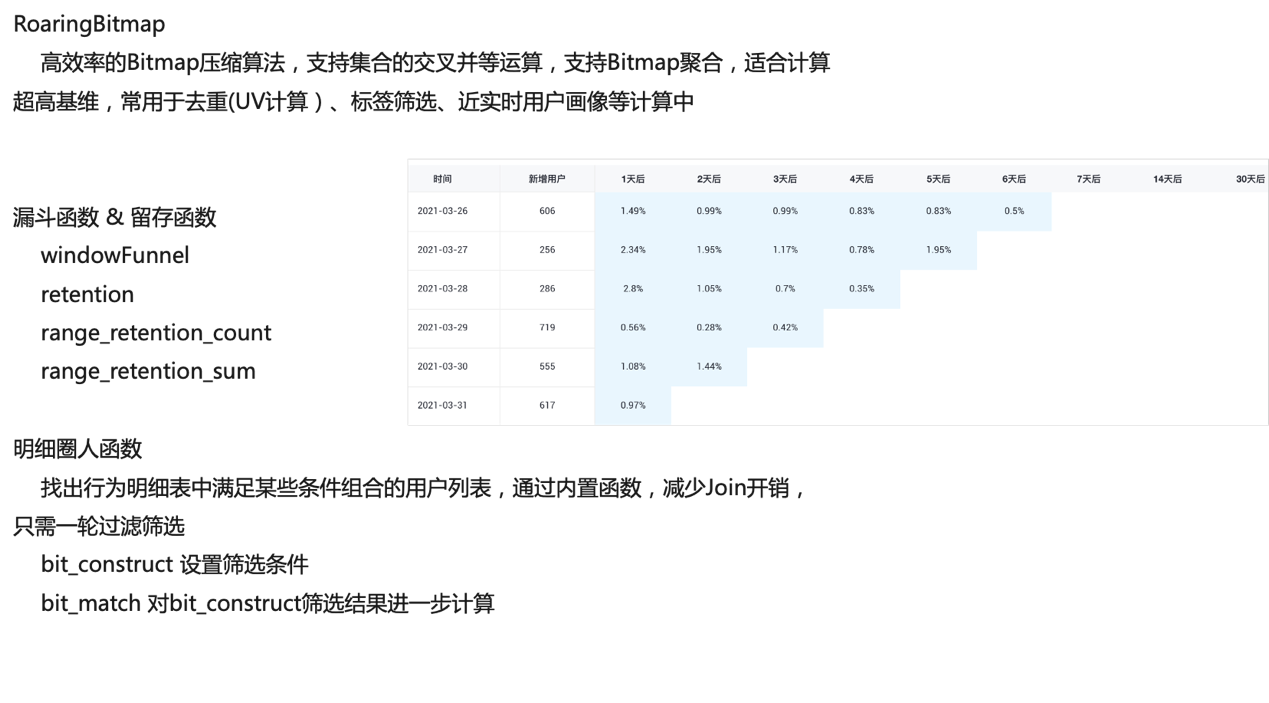
同时Hologres也内置了更多的漏斗分析、留存分析、明细圈人等函数,通过这些内置的函数,极大的简化了开发的工作,也保证了复杂操作的执行效率。详情使用见文档流量分析
多负载资源隔离
资源组隔离是有效支撑混合负载的一种手段,Hologres支持了单实例多资源组的设计,在这个设计中,总的计算资源被划分为若干资源组,不同的资源组表示了一定的CPU和内存资源,同时设定用户与资源组之间的绑定关系,绑定之后,用户只能使用对应资源组的计算资源,所有未绑定的用户会使用系统默认的Default资源组。目前资源组之间资源不共享,不抢占,资源组内部多个用户共享同一组资源。
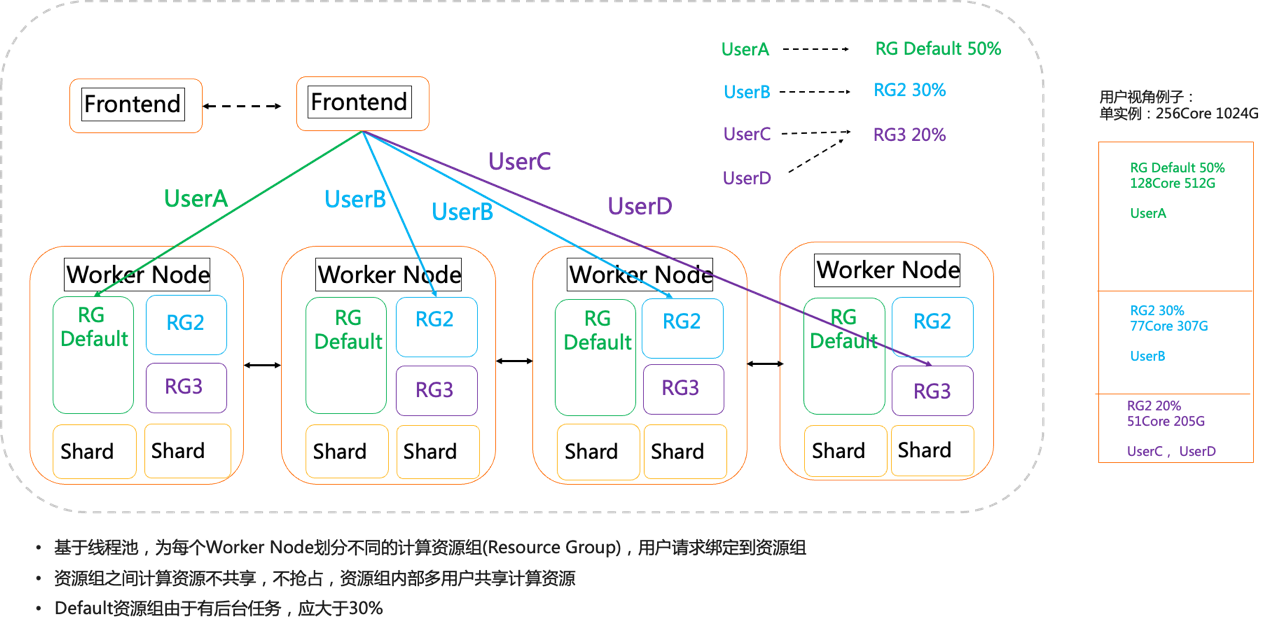
如上图的右侧是一个用户视角的划分,一个256Core1024G的实例,划分为3个资源组,不同的应用场景采用不同的账号,比如OLAP分析用Default资源组,分配50%,在线点查需要20%的资源,而数据实时写入分配30%的资源。通过资源组的隔离能力,避免了Bad Query把全部资源吃尽的问题,可以根据业务优先级分配资源。详情使用见资源组隔离
高可用部署
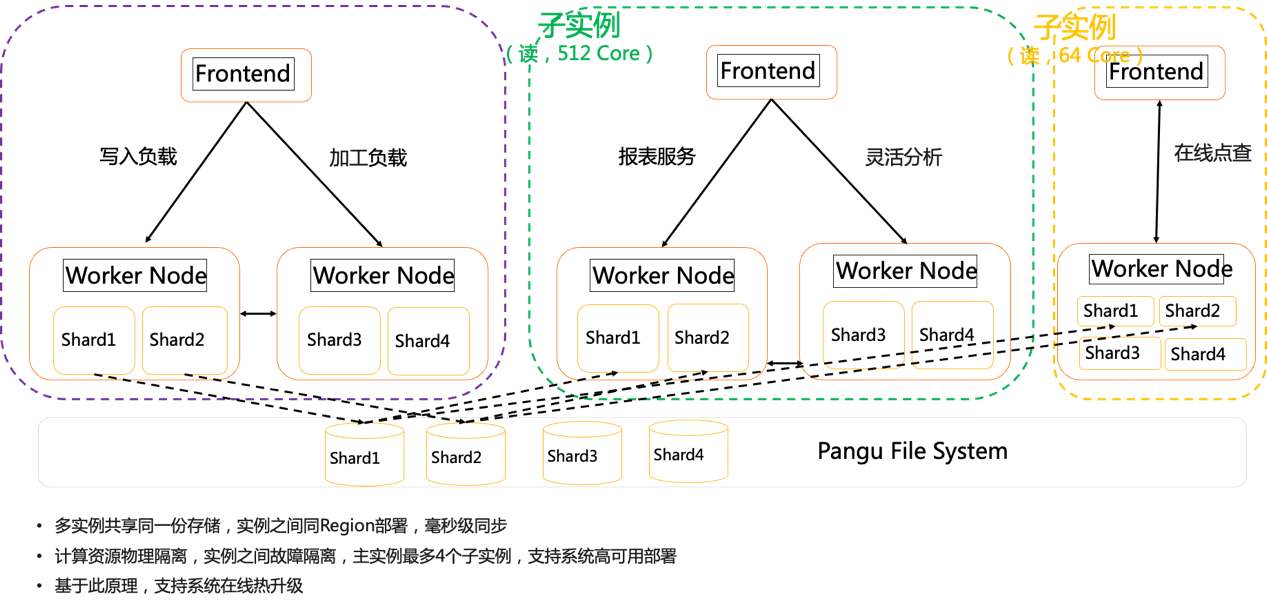
资源组隔离是一种单实例内部不同线程池之间的计算资源的隔离,无法做到故障隔离和100%的读写隔离。因此Hologres继续创新更好的高可用方案,在V1.1版本,支持了共享存储的多实例部署方案。在该方案中,主实例具备完整能力,数据可读可写,权限、系统参数可配置,而子实例处于只读状态,所有的变更都通过主实例完成,实例之间共享一份数据存储,实例间数据异步实时同步,延迟在毫秒级别。
应用场景:
1.读写分离:这个方案实现了完整的读写分离功能,保障不同业务场景的SLA,在高吞吐的数据写入和复杂的架构作业、OLAP、AdHoc查询、线上服务等场景中,负载之间物理上完全隔离,不会因写入产生查询的抖动。
2.多类型负载细粒度资源分配:一个主实例可以配置多个只读从实例,实例之间可以根据业务情况配置不同规格,例如使用256Core作为写入和加工实例,512Core作为OLAP只读实例,128Core作为在线Serving实例,32Core作为开发测试实例。
在线服务高可用:任何系统都有不稳定的时刻,磁盘损坏,系统Bug等等,在支撑在线高可用服务场景下,需要在系统级别支撑冗余的高可靠能力,在一个服务系统出现故障时,可以快速切换到备用系统上,且切换的时间要尽量短,数据状态保持一致。可以通过部署多个子实例的模式,提供多个Endpoint接入,当某个实例出现故障时,应用层可以快速切换到其他Endpoint上,实现了系统的高可用和灾备切换。
详情使用请见文档高可用部署。
增强系统可观测性
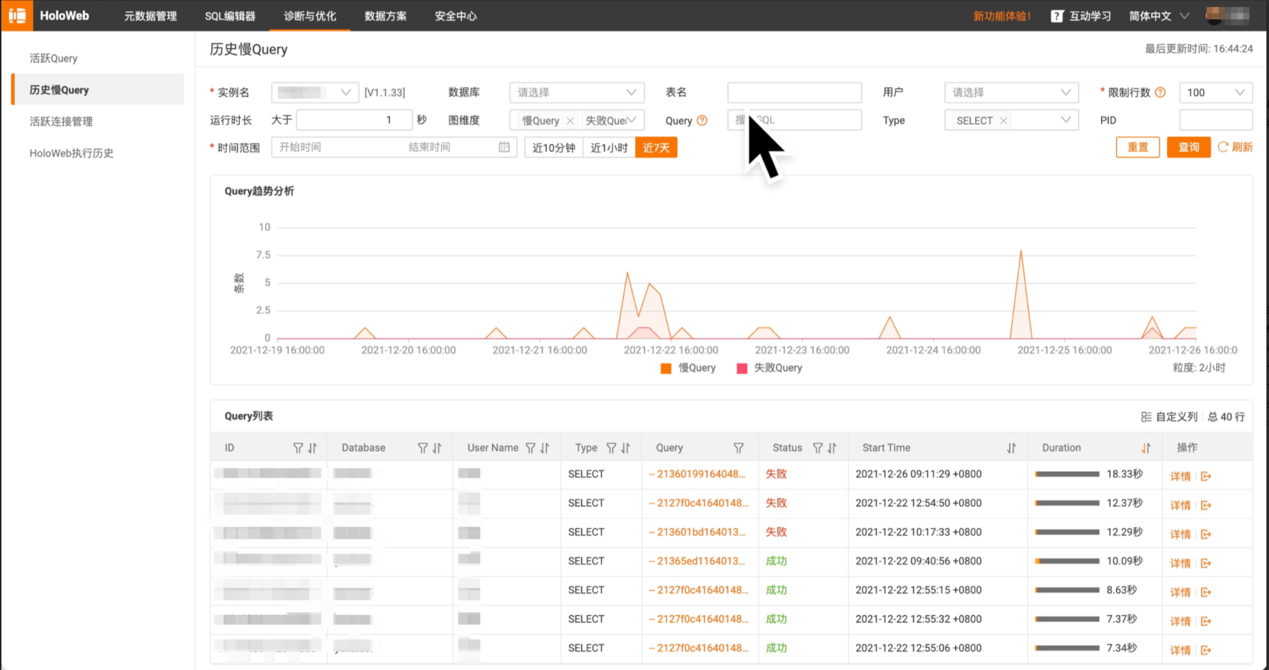
系统可观测性通过HoloWeb持续可视化透出,包括慢查询、执行计划、活跃连接等,提升企业自运维能力:
·慢Query日志:支持对系统中发生的慢Query或失败Query通过时间、plan、cpu消耗等各项指标进行诊断、分析和采取优化措施,提高自助诊断能力。详情见慢query日志。
·活跃连接:通过对活跃连接的可视化查看,定位连接状态、连接数以及用户等的情况,以达到分析实例连接状态和诊断运行SQL的目的。详情见文档连接数管理。
·执行计划:通过多种可视化展现的方式,对Query进行运行分析、执行分析,详细算子解读,并进行优化建议引导,避免盲目调优,降低性能调优门槛,快速达到性能调优的目的。详情见执行计划。
企业级安全能力升级
企业级安全能力再次升级,支持数据加密、访问控制、容灾备份等:
1)数据加密:
·基于密钥管理服务KMS(Key Management Service)对数据进行加密存储,提供数据静态保护能力,满足企业监管和安全合规需求。详情见文档数据加密
·与MaxCompute无缝打通,支持加速MaxCompute加密数据,向实时离线一体化更进一步。详情见文档访问MC加密数据。
·支持数据脱敏,对接数据保护伞,提升数据隐私性。详情见数据脱敏。
2)访问控制
·支持IP白名单,实现更加细粒度的安全访问,详情见IP白名单
·对接ActionTrial,支持实例级别行为审计,详情见审计
3)容灾备份
·支持同城跨机房容灾(专有云)
·支持容灾,异地多活,并实现读写分离和读的高并发,同样也可以基于多个实例实现读的高可用。除此之外,还可以进行版本热升级,存储系统迁移。

PG生态兼容
支持更加丰富的数据类型、更多元的扩展函数,同时在BI可视化分析上持续发力,无缝对接更多BI工具,降低学习门槛,也向PostgreSQL兼容更进一步。详情见函数列表。
持续专注于一站式实时数仓
Hologres未来会继续专注在实时数仓的可靠性、效率和可运维能力上,致力于Real-time,专注于One SQL、One Data,提升企业级可运维性,降低开发门槛,实现企业级一站式实时数仓的终极目标。具体会在以下方面发力:

Real-Time
简化实时数仓的开发体验,支持Pull模式,主动从上游的消息中间件拉取数据,简化数据落库的过程。正在研发实时物化视图的能力,通过实时物化视图,用户可以把复杂的加工逻辑描述为视图的定义,Hologres保证视图与表之间的实时同步特性,通过SQL表达数据的加工逻辑,实现数据分层的实时化,与数据流动的自动化。
OneSQL
完善Hologres SQL的表达能力,支持OLAP/Serving/AI多个场景,持续改善稳定性和效率,不仅要查的快,更要查的稳。持续优化实时离线一体化体验,进一步减少数据移动的需求。完善JSON的各类索引和压缩效率。会支持UDF能力,完善可扩展性,将更多的扩展可能性交给用户。对计算资源的弹性也是重点方向。
OneData
进一步与DLF、MaxCompute、EMR等存储和元数据系统打通,避免数据孤岛,支持湖仓一体解决方案。正在研发存储冷热分层,在SSD基础上引入HDD,可以显著降低用户的存储成本。
Ops
最后是可运维性,会持续在系统可观测、可调优发力,避免系统黑盒话,支持系统热升级、热扩容,降低运维风险。会极大改善数据治理能力,与DataWorks合作,支持更多的元数据分析与诊断。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com


