作者:国工智能研发部—陈渝敏
业务背景
不管是制造业还是化工行业,对于成本或产量控制、预测、决策都是生产管理中的重要组成部分。以成本控制为例,过去人们对成本控制的认识比较狭隘,传统的成本控制范围局限于制造产品的过程,例如对成本形成过程中一些耗费指标的控制,使它不超过定额预算,如果发生差异,进行差异计算和差异分析,以达到降低成本的目的。所以,传统成本控制重点在生产过程中的差异计算和结束生产过程后的差异分析,是一种消极的成本控制。同时,企业耗费大量人力,物力收集的数据及指标信息并没有得到很好的利用,只是停留在表面的分析。而借助国工数据大脑平台的多元线性回归分析算法,不但可以做到对成本的事先控制,即对企业未来几年的成本进行预测,还可以及早发现企业投入的成本不足或成本过剩的现象,帮助组织明确未来成本需求趋势,做好成本规划工作,从而进行准确决策;而且可以复用历史成本数据深度挖掘出有用的信息,探索出具有一般规律性和普遍适用性的成果。
多元线性回归定义
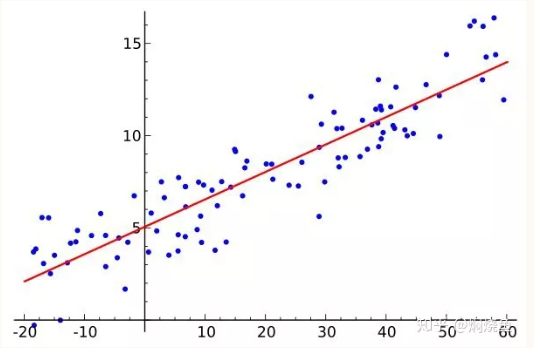
回归分析是作为数据科学家需要掌握的第一个算法,是数据分析中最基础最重要的分析工具,绝大多数的数据分析问题,都可以使用回归的思想来解决。回归分析的任务就是,通过研究自变量X和因变量Y的数学关系式进而达到通过X去预测Y的目的,它是数据分析中最常用的预测建模技术之一。即使在今天,大多数公司都使用回归技术来实现大规模决策。其中包括了一元线性回归方法、多元线性回归方法和非线性回归方法等。(线性指的是X、Y之间呈线性关系,不管X取什么值,都能在这条回归直线上找到对应的Y,如图1,只要输入X,Y的样本数据,数据大脑中的拟合回归算法就能得到相应的回归直线)
图1
界定线性回归是否为多元,主要看自变量(即X)的个数,若自变量个数在两个及其以上,则称其为多元线性回归,显然若自变量个数有且只有一个,称为一元线性回归。多元线性回归的基本原理和一元线性回归完全相同,区别只在于自变量的个数。
在实际中,一个指标的影响因素通常不止一个,而是有若干个重要因素共同作用才导致事物的发展变化,因此在实际分析时多考虑多元回归分析,本文以较为复杂的多元线性回归为例。多元线性回归模型的一般形式为:
Y=a0+a1*X1+a2*X2+a3*X3…
Y指的是因变量,即我们关注的指标(成本或产量等);X指的是影响Y的因素。a1,a2,a3……指的是影响程度的大小(又称回归系数大小)。
回归分析的应用
回归分析用于在许多业务情况下做出决策。回归分析有三个主要应用:
1.解释企业理解困难的事情。例如,为什么在上一季度的营业额有所下降。
2.预测重要的商业趋势。例如,明年会要求他们的产品看起来像什么?
3.选择不同的替代方案。例如,我们应该选择原料A还是原料B?
进行预测的前提
当我们求出回归模型的具体表达式时,还需要进行统计意义检验,通过检验才能使用该模型进行预测。主要包括:拟合优度检验、回归模型的总体显著性检验和回归系数的显著性检验等。
1. 拟合优度检验
拟合优度是指拟合的回归模型与样本观测值之间的接近程度。即衡量一个回归模型做的好不好的指标。用决定系数(R-sq)表示,其数值区间为 0 —— 1,越接近1,说明模型拟合得越好。判断标准为:大于或等于0.7,认为拟合优度较好;在0.35——0.7之间,认为拟合优度较普通;小于0.35,认为拟合优度较差。
2.回归方程的显著性检验
即检验整个回归方程的显著性,或者说评价所有自变量x整体与因变量Y的线性关系是否密切,整个回归方程本身是否有效。通常采用F检验。
3.回归系数的显著性
若方程通过显著性检验,并不意味着每个自变量对y的影响都显著,所以就需要我们对每个自变量进行显著性检验。若某个自变量系数对y影响不显著,即无关的变量。我们需要从回归方程中将其剔除。通常采用t检验。
应用场景
成本高低不仅影响着化工行业企业的利润,更是其公司发展壮大的一个制约因素。某有机新材料企业想要减少化学反应中的原料剩余并预测在某种反应参数变量取值下的原料剩余。原料剩余越少,成本利用率越高。把我们想要研究的对象原料剩余(Y)作为因变量,选取了4个主要影响因素:原料A的SM(X1);原料B的硝酸(X2);温度(X3);反应时间(X4)。并进行22次试验。基于22次实验数据进行多元线性回归。
初步得到线性回归方程:Y=a0+a1*X1+a2*X2+a3*X3+a4*X4。
首先,利用数据大脑中的多元线性回归组件,就可得到回归系数:a1,a2,a3,a4的值。即把多元线性回归组件拖到到工作面板,配置数据及组件参数:将因变量和4个自变量分别拖到对应的区域。过程如图1:

图1
配置好参数之后,其次点击运行,结果如下:
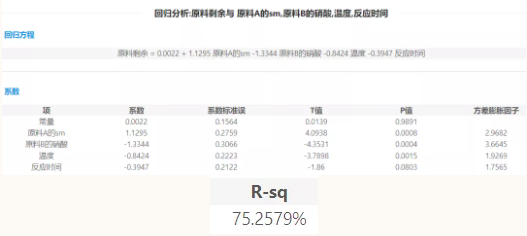
图2

图3
由图2可知,关于拟合优度检验方面,决定系数R-sq(即R方)=0.7526,说明该模型拟合优度较好,因变量Y与自变量X1,X2,X3,X4具有较高的线性相关关系。
从图3可知:对于F检验,查F分布表可知,显著性水平为0.1所对应的F临界值是2.31,F检验统计量的值为5.5,故F统计量的值>临界值,拒绝原假设。说明整个回归模型是有效的,所有自变量整体对Y有影响。
对于t检验,由图2 显示,在0.1的显著性水平下,四个自变量的p值分别为:p1=0008;p2=0.004;p3=0.0015;p4=0.0803,均小于0.1,故拒绝原假设,进一步表明每一个自变量对Y有显著影响。综上,所有结果显示此回归模型通过了统计意义的检验,说明此四元线性回归模型是成立的,可以用于预测。
已知a1=1.130,a2=-1.334;a3=-0.842;a4=-0.395。
最终的多元线性回归方程为:Y=0.002+1.1295 X1-1.3344 X2-0.8424X3-0.395 X4
此方程的意义是:在假定其它自变量不变的情况下,原料A的SM(X1)每增长1g,原料剩余就增长1.1295g;在假定其它自变量不变的情况下,原料B的硝酸(X2)每增长1g,原料剩余就减少1.3344g;在假定其它自变量不变的情况下,温度(X3)每提高1摄氏度,原料剩余就减少0.8424g;在假定其它变量不变的情况下,反应时间(X4)每提高1秒,原料剩余就减少0.395g;同时,回归系数a的绝对值越大,对Y的影响越大,可以看出a2的绝对值最大,为1.334。在决策方面,若该企业想减少原料剩余率,应当多关注原料B的情况。
在预测方面:若下一次实验时,假设X1=1.260,X2=-0.371,X3=-0.670;X4=0.770,则Y的预测值=0.002+1.1295*1.260-1.3344*(-0.371)-0.8424*(-0.670)-0.3947*0.770=2.179(g)。即原料剩余为2.179g,该企业可以将其与上一次实验进行比较,从而进行相应的决策。

国工智能是一家专业为流程制造业提供人工智能决策控制整体解决方案及落地服务的国有参股高新技术企业,专注于利用人工智能、大数据等技术解决流程制造业海量数据下复杂场景的智能制造需求,为客户提供“IOT+AI+OR”智能制造人工智能整体解决方案。目前,公司已经成为化工新材料行业人工智能决策控制领域的领跑者。
作为一家国内专业的智能制造落地服务商,国工智能凭借深厚的内功和优秀的团队,自主研发了基于人工智能的数据大脑分析平台(MAI)、智能制造管理平台(MES)、物联网数据采集平台(SCADA)、实验室管理系统(LIMS)、双体系设备管理系统(EMS),均在行业内成功应用。

国工智能在化工、医药、食品、饲料、新材料等行业深耕已久,客户遍布全国,已成功为海大集团、华润三九药业、康缘药业、丰原集团、道恩集团、九目化学、蓝帆医疗、新时代健康产业集团、安然纳米集团等客户提供智能制造落地服务。

国工智能秉承“利于国,精于工”的企业发展理念,以高端IT技术服务于传统制造企业,推动国家制造业转型升级,以工匠精神为中国智造赋能!努力成为科技创新和产业革命的引领者,为中国实体经济崛起、实现中国制造2025贡献力量!

国工数据大脑系统(MAI-CLI)是一个集数据调度,数据清洗,数据计算、数据可视化的数据分析平台。系统以简单易用拖动操作方式进行人机交互,屏蔽了数据分析预测业务的复杂性,大大降低了数据分析工作的技术门槛。
以计算流的方式构建整个数据分析业务。平台实现了对分散的数据进行统一调度,实现实验室设备、工业传感器、信息化系统接口多源数据整合。
平台提供上百个功能组件,包含方差、回归、聚类、分类、时间序列等算法组件,支持SPC、DOE、CPK、MSA等分析理念,平台拥有定时分析功能,可以同时监控上万的质量监控点。能实现自动化六西格玛实施落地。
应用场景
计划经理可以用来预测未来销售情况,并自动跟踪执行。
质量经理可以用来做SPC分析、取样差异、方差分析。
研发经理可以做配方优化预测、实验辅助设计、工艺分析、数据仿真。
设备经理可以用来做设备预测性维护、报警。
平台已经完成边缘计算封装,可以与设备进行互动。
同时所有算法对软件开发商开放调用,可以用来做底层算法平台。
(数据大脑同时提供算法商城服务,任何伙伴都可以使用多编程语言开发算法,由国工智能进行测试回购。)
数据大脑人工智能计算平台背后拥有强大的数据分析团队,您提需求我们解决。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com