多模态、预训练排序是当下的热门话题,同时也将会是未来金融行业的主攻方向之一。一直以来,度小满关注创新技术的发展,加强创新技术在金融领域的运用,在多模态、预训练排序等领域取得出色的成绩。日前,由度小满数据智能应用部AI-Lab撰写的两篇论文,对多模态和预训练排序提出新颖算法,获得了业界的高度关注。
度小满两篇论文对多模态和预训练排序提出新颖算法
近日,度小满数据智能应用部AI-Lab的两篇论文分别入选ACM MM和CIKM国际顶级会议。两篇论文分别就多模态和预训练排序等多个热门话题提出了新颖的算法,并在相关任务上达到了国际顶尖水平,获得了审稿人的一致好评并最终录用。这标志着度小满在自然语言处理和计算机视觉等人工智能前沿领域的研究得到了国际同行的认可。

其中,度小满论文中具有实体对齐网格的位置增强Transformer被ACM MM录用。据了解,许多图像除了实际的物体和背景等信息外,通常还包含着很有价值的文本信息,这对于理解图像场景是十分重要的。因此度小满这篇论文主要研究基于文本的视觉问答任务,这项任务要求机器可以理解图像场景并阅读图像中的文本来回答相应的问题。然而之前的大多数工作往往需要设计复杂的图结构和利用人工指定的特征来构建图像中视觉实体和文本之间的位置关系。为了直观有效地解决这些问题,度小满科研团队提出了具有实体对齐网格的位置增强Transformer。
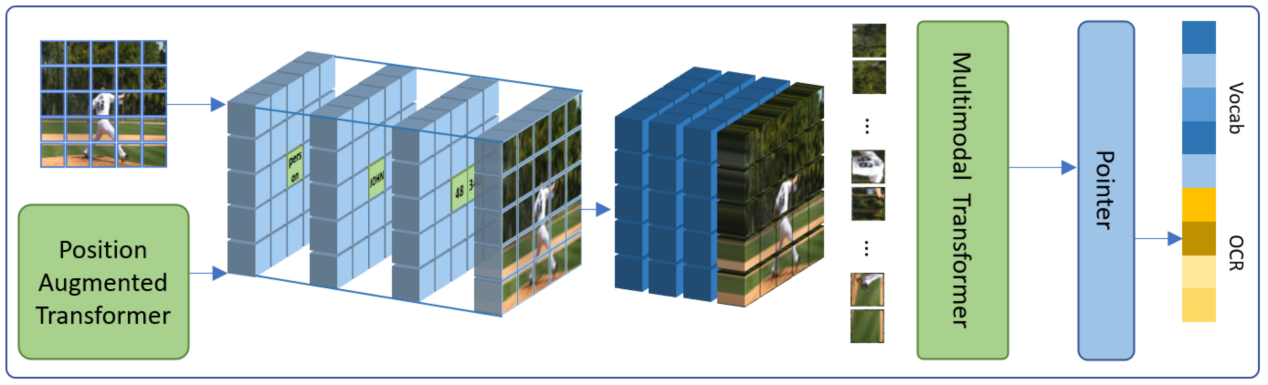
该模型能够整合目标检测、OCR以及基于Transformer的文本表示等多种方法的优势,增强算法对于图像中场景信息的理解,更精准的融合图像与文本多模态的信息,进一步助力证件识别、人脸与活体检测等业务场景,提升度小满在视觉风控方面的技术能力。
度小满布局预训练语言模型,广泛运用于金融服务场景中
而度小满另一篇论文中基于BERT的动态多粒度排序模型被CIKM录用。近年来,预训练的语言模型广泛应用于文本的检索排序任务中。然而,在真实场景中,用户的行为往往受到选择或曝光偏差的影响,这可能会导致错误的标签进而引入额外噪声。
而对于不同候选文档,以往的训练优化目标通常使用单一粒度和静态权重。这使得排序模型的性能更容易受到上述问题的影响。因此,在度小满这篇论文中科研人员重点研究了基于BERT的文档重排序任务,开创性地提出了动态多粒度学习方法。此外,该方法还同时考虑了文档粒度和实例粒度来平衡候选文档的相对关系和绝对分数。
该模型有效地提升了长文本理解与排序任务的性能,特别是其中所用到的预训练语言模型已经成为度小满在自然语言处理方面的基础架构,在获客、信贷等业务场景被广泛地使用,为业务模型提供了更加丰富的文本表示和精准的文本特征,在保障业务稳健发展中起到了十分重要的作用。
各种创新技术的诞生和应用,为金融服务产业的发展带来了诸多机遇。可以说,加强技术创新,将会是企业抢占金融服务市场先机的有效途径之一。相信在以度小满为代表的一批创新金融科技企业的共同努力下,未来金融服务行业将拥有更多可能性。



