6月8日记者获悉,ICPR2022多模态字幕识别比赛(Multimodal Subtitle Recognition简称MSR竞赛)日前正式结束,共有376位来自各大高校和企业的选手参赛。
网易浙大华科联合团队、好未来、Yidun AI Lab获赛道一前三名,网易、大搜车、Yidun AI Lab获赛道二前三名,Yidun AI Lab、中科院自动化所、好未来获赛道三前三名。
作为国内首个多模态字幕识别大赛,本次竞赛由腾讯 OCR & ASR Oteam 联合华南理工、华中科技大学、联想等依托于计算机国际学术顶会ICPR举办。大赛从多模态角度出发,创新性地提出从画面和语音联合的字幕识别框架,希望推动字幕识别技术的准确性和应用性的进一步提升,弥补该技术领域的空白,并为学术界和业界创造交流机会。
在日常生活中,人们认知世界的过程总是多模态的。个体对场景进行感知时会接收到多种信号,如视觉、听觉、嗅觉等。因此,多模态机器学习方法更贴近人类认识世界的形式,也是人工智能技术取得进一步进展的基石。比如通过对视频、音频、文本等多种模态数据进行联合解析,模型可以更充分的理解广告内容,优化广告内容和提升广告投放效果。
观众在观看视频时,往往会接收到两类信号,即视觉和听觉,通过这两类信号,观众可快速且准确判断视频字幕的内容。 然而,受限于各种原因,字幕识别技术目前大多基于单个模态,仅利用单模态信息,视频字幕提取的准确性较差。例如,音频对背景噪声和口音变化很敏感,有些方言或谐音词难以准确识别,但是如果加入视觉信息,那么上述问题可以很容易得到解决。
腾讯ASR&OCR Oteam首次提出在字幕识别技术中引入了多模态技术,弥补了这一技术在业内的空白。
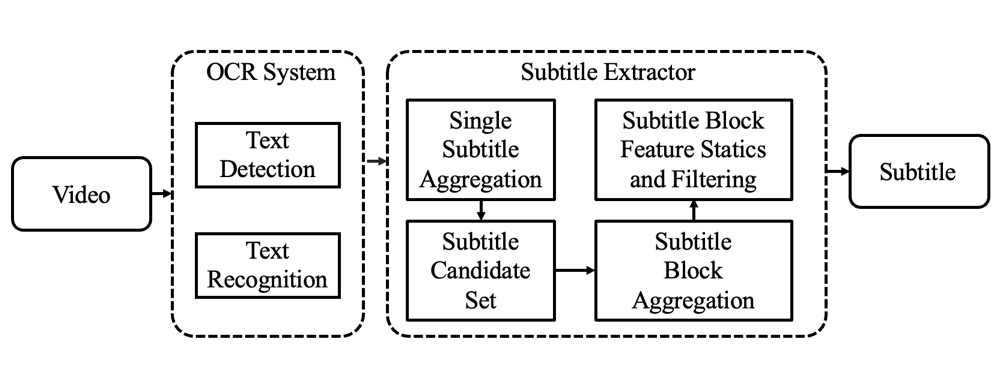
在赛道一“使用含有音频字幕标注的数据,来训练视觉模态的字幕识别系统”中,字幕标签由腾讯 ASR Oteam提供。来自网易、浙大、华科联合团队Jingquntang etal设置的冠军方案模型主要分为三个部分:文字检测、文字识别以及字幕提取部分。由于字幕标注信息是跨模态的弱监督标注数据,因此文本识别模块难以训练。为了解决该问题,冠军方案使用构造数据的方式来解决该问题。首先,该方案使用文本检测模块检测视频帧中的文本并将文本进行抹除。接着,该方案将音频提供的字幕信息与抹除文字后的帧生成新的视频帧。该方案使用生成数据对文本识别模块进行训练。字幕提取模块对比前后帧的字幕内容、IoU信息、和文本框位置提取字幕。
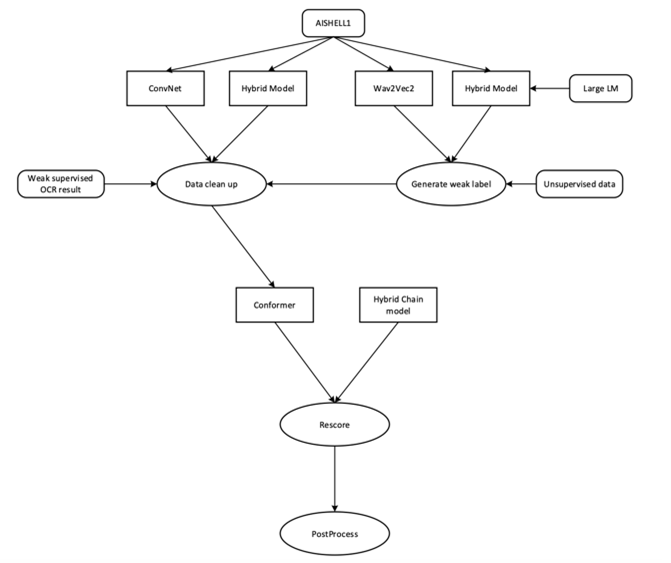
在赛道二“使用含有视觉模态字幕标注的数据,来训练音频字幕识别系统”中,腾讯OCR Oteam提供了字幕标签。来自网易的nickyang etal队伍设置的冠军方案,同时训练了若干个ASR模型,并将所有模型的输出融合为最终结果。在数据预处理部分,对于含有字幕标注的训练集,冠军方案通过构建解码图,并应用简单的卷积网络计算语句置信度,得到文本标注信息;对于不含字幕标注的训练集,冠军方案使用微调的wav2vec2.0模型得到文本的语言特征,再使用预训练的语言模型和Kaldi解码器得到文本标注信息。然后,在模型训练部分,该方案分别使用了混合模型和端到端的Wenet模型共同训练,并通过循环往复的方式得到更优的训练集标注,进行更新迭代,从而得到了最优的文本识别结果。
相比于赛道一、二,赛道三“旨在融合视觉和音频两个模态的信息来设计字幕识别系统”的系统设计则更加复杂,腾讯 ASR和OCR Oteam 打造了语音和画面联合字幕识别的算法框架。来自GrowthEase Yidun AI Lab的robindu etal队伍设置的冠军方案中主要包含三个模块:视觉模态的字幕提取器,音频模态的字幕提取器,融合模块将两个模态结果进行融合。其中,前两个模块主要是基于OCR、ASR系统开发的。
模型首先判断视频是否含有两个模态的字幕信息。若预测视频只包含单个模态的字幕信息,则字幕结果只取单模态的字幕信息。如果两个模态的字幕信息,则进一步使用融合模块来融合两个模态的结果。两个模态的字幕信息在时间上可能存在偏移,例如,在音频内某些谈话内容已经开始,而视觉字幕仍停留在讲话者的前一句内容。为了解决该问题,即将视频中所有字幕能按序拼接,该方案设计了拆分模块。该模块将两个模态中相同和不同的字幕文本进行拆分。在两个相同的字幕文本部分,针对某条视觉字幕可能会在多个帧中存在。对于不同帧的背景干扰导致同一字幕的识别结果不同这一问题,融合模块中的过滤模块旨在挑选视觉字幕中OCR识别效果最好的,同时移除识别效果不好的。最后,将不同的部分和相同的部分字幕文本使用填充模块进行拼接。

作为腾讯开源协同小组,腾讯ASR和OCR Oteam通过对内部优势技术的整合和开源,构造了贴合各类业界场景的完整、先进、鲁棒的模型库和算法框架。后续将会对业界开放基础算法框架,同时也寻求学术和工业界在该问题的先进算法和技术,携手共建更优的多模态字幕识别解决方案。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com