近年来,随着智慧城市、自动驾驶、工业互联网等应用的广泛推广,终端设备所产生的数据量呈爆炸式增长,使得集中式云计算在带宽负载、网络延时和数据管理成本等方面愈加捉襟见肘,由此催生了边缘计算价值的进一步突显。如今,自动驾驶、工业自动化、智慧医疗和物联网等各行业对边缘计算的需求呈现了大规模增长态势。
随着边缘计算应用范围的不断扩展,数据量也持续增长,于是各行业对计算量级和实时性提出了更高的要求;而芯片作为算力实现的核心,则成为了整个行业迫切的需求,市场对于芯片的需求也不再只是单一的算力和功耗,更加强调芯片的通用性、可编程和可扩展性,以此来满足不同场景下的应用需求。各大芯片厂商也需要不断创新,研发更加通用、高性能和高能效的芯片。
逆势而上,加快国产替代
在通用计算芯片这个成熟市场,强势的英伟达、AMD、英特尔三分天下,令后来者难以立足,我国芯片企业想要撕开一道口子,必须另辟蹊径;或从架构、制造工艺、新型材料、新的器件结构等都要进行创新。
在技术路线方面,成熟的GPU架构已经存在长达几十年之久,形成了比较完整的生态系统。国内虽有多种GPU架构,但却缺乏全球竞争力的自主GPU架构;我国目前GPU产业发展呈现两种趋势:一是追逐传统GPU架构,它的成熟度较高,但是属于跟随路线,作为市场的后来者,技术上不成熟,性能上不先进是很难切入市场;二是采用自主研发的新型架构,攻坚难度大,但是有取胜的可能性。
智能互联世界,GPU架构格局或有变化。
珠海市芯动力科技有限公司(简称芯动力)创始人指出,为了满足高效的并行计算,可以采用脉动阵列的方式来处理,同时继承广为人们所接受的CUDA语言,这样可以同时满足高算力的需求,也不影响用户的使用习惯。
经过十余年的探索,芯动力研究了并行计算的本质,发现了一种更加适合并行计算的处理器架构,能够在不改变程序的基础上更有效的执行CUDA语言的程序。并且在2017年成功研发出可重构并行处理器(RPP)架构。芯动力开始向GPU领域进军。
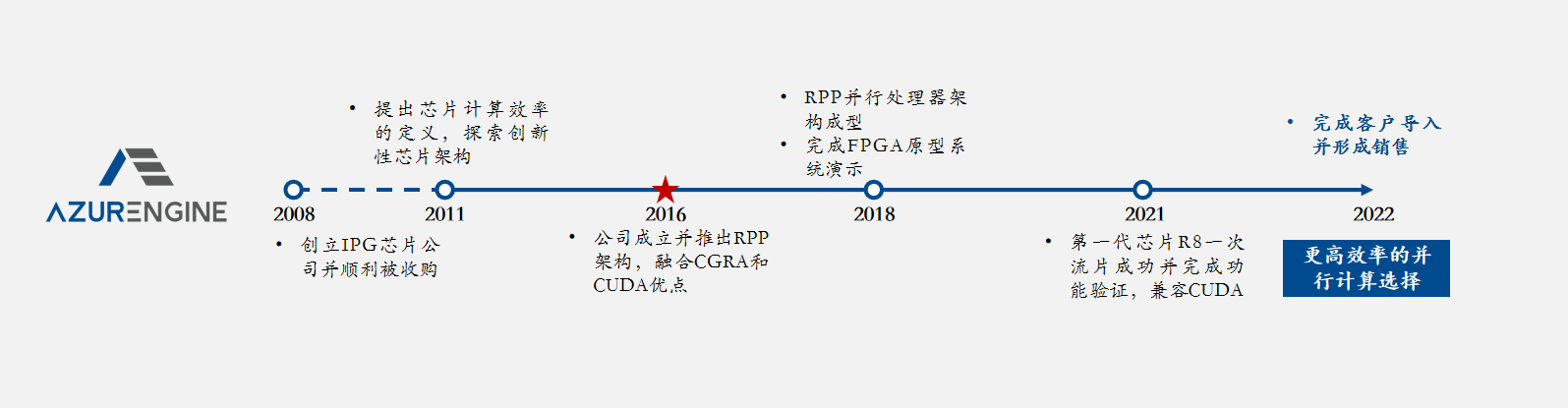
RPP架构主打并行计算,并且借助于独有的底层硬件架构,成功地实现了对CUDA语言的支撑。不仅如此,芯动力还拥有自主开发的工具链,包括独立的SIMT指令集和后端编译器,使得其能够在cuDNN和TensorRT上实现API的兼容,同时也支持广泛的人工智能框架,如TensorFlow和Pytorch等。
芯动力团队认为,通过工具链的开发,RPP能够对于AI推理的性能进行深度优化,从而在高性能计算领域中实现了最广泛使用编程语言的支持。这种兼容不仅从底层的软件兼容性方面体现,同时也可以提升用户的使用体验,满足用户在调用形式、使用感知等方面的需求。做这种生态是因为观察到CUDA语言体系里,开放体系比较完整,第三方开发的软件都是以源代码的形式开放给社区,而不像CPU的生态领域里存在大量的二进制代码,因此,支持CUDA语言就能够广泛的支持GPGPU的生态。
并且,以RPP架构为基础面向边缘市场设计的第一代芯片RPP-R8已经一次性流片成功,芯动力正式开启踏入GPGPU领域的市场。

据悉,RPP-R8芯片是一款具备高算力与低功耗的通用型GPGPU芯片,每颗芯片内含有1024个计算核,与传统的GPU架构相比,在同样的算力占用更小的芯片面积,实现了低功耗和高能效的有效平衡。RPP-R8除了具备专用芯片所没有的通用编程性,面积效率比可达到同类产品的7~10倍,能效比也超过3倍,可满足高效并行计算及AI计算应用。
GPGPU是GPU未来的重要趋势之一,也是国产的一次机会。
据IDC预测,到2024年,全球边缘计算市场(包括软件、硬件和服务)将达到2506亿美元,年增长率为15.9%。其中,中国边缘计算服务器市场将达到855,334台,硬件价值预期55亿美元。芯动力研发上市的RPP-R8芯片具备低时延、高算力、低功耗、高能效、编程灵活等诸多优势,非常适用在边缘计算场景,通过市场的反馈,软件商可以更快的部署,基本一天就可以完成迁移。
RPP-R8的应用从本质上可有效帮助企业降低开发成本和产品周期,加速产品迭代与扩展。目前这款芯片应用场景已覆盖工业自动化、智能驾驶、泛安防、物流检测、内容过滤、信号处理等多领域,未来将跨入更广阔的市场。
当前,算力已成为数字经济时代的核心生产力,随着信息化、数字化和智能化进一步加快,新一轮的算力革命正在加速启动。芯动力作为一家专注于研发新一代可编程通用并行计算芯片的企业,在珠海、深圳、西安、美国都设立了研发中心,专注攻关核心关键技术,加快国产替代,使得算力在技术层面不断突破技术壁垒。
在目前算力增长的时代,很多芯片厂商依赖于先进的工艺来实现芯片的高算力, 在中国半导体工艺被严重卡脖子的时代,架构的创新显得尤为重要,以架构的创新来替代先进工艺所带来的算力提升是芯动力一直发展的方向。
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com


