关键词:AIGC;NLP;ChatGLM;AGI;LLAMA;BERT;GLM;LLVM;LSAT;ChatGPT;深度学习;高性能计算;大语言模型;大型语言模型;CPU;GPU;HPC;液冷服务器;GPU服务器;GPU工作站;蓝海大脑;人工智能;液冷散热;A100;V100;A800;H100;H800;AI;水冷工作站
日前,随着深度学习、高性能计算、大模型训练等技术的保驾护航,通用人工智能时代即将到来。各个厂商也都在紧锣密鼓的布局,如AMD MI300X 其内存远超120GB的英伟达GPU芯片H100,高达192GB。
6月22日,英特尔(Intel)宣布,美国能源部阿贡国家实验室已完成新一代超级计算机"Aurora"的安装工作。这台超级计算机基于英特尔的CPU和GPU,预计在今年晚些时候上线,将提供超过2 exaflops的FP64浮点性能,超越美国能源部橡树岭国家实验室的"Frontier",有望成为全球第一台理论峰值性能超过2 exaflops的超级计算机。
Aurora超级计算机是英特尔、惠普(HPE)和美国能源部(DOE)的合作项目,旨在充分发挥高性能计算(HPC)在模拟、数据分析和人工智能(AI)领域的潜力。该系统由10624个刀片服务器组成,每个刀片由两个英特尔Xeon Max系列CPU(至强Max 9480)和六个英特尔Max系列GPU组成。
英伟达前段时间发布GH 200包含 36 个 NVLink 开关,将 256 个 GH200 Grace Hopper 芯片和 144TB 的共享内存连接成一个单元。除此之外,英伟达A100、A800、H100、V100、H800也在大模型训练中更是广受欢迎。
那么英伟达A100、A800、H100、V100、H800等卡为何广受欢迎,国内厂商又是如何布局的呢?下面让我们一起来看下。

一、英伟达大模型训练GPU全系列介绍
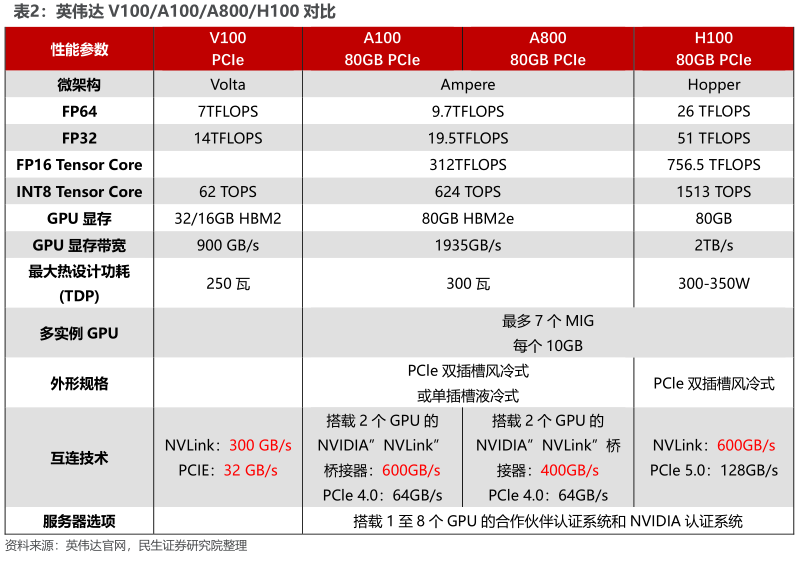
自OpenAI发布ChatGPT以来,生成式人工智能技术一直是备受关注的热门趋势。这项技术需要强大的算力来生成文本、图像、视频等内容。在这个背景下,算力成为人工智能领域的必备条件,而英伟达作为芯片巨头所生产的人工智能芯片在其中扮演着至关重要的角色。英伟达先后推出V100、A100和H100等多款用于AI训练的芯片,并为了符合美国标准,推出了A800和H800这两款带宽缩减版产品,在中国大陆市场销售。
V100是英伟达公司推出的高性能计算和人工智能加速器,属于Volta架构系列。它采用16nm FinFET工艺,拥有5120个CUDA核心和16GB到32GB的HBM2显存。V100还配备Tensor Cores加速器,可提供高达120倍的深度学习性能提升。此外,V100支持NVLink技术,实现高速的GPU到GPU通信,加速大规模模型的训练速度。V100被广泛应用于各种大规模AI训练和推理场景,包括自然语言处理、计算机视觉和语音识别等领域。
A100是英伟达推出的一款强大的数据中心GPU,采用全新的Ampere架构。它拥有高达6,912个CUDA核心和40GB的高速HBM2显存。A100还包括第二代NVLink技术,实现快速的GPU到GPU通信,提升大型模型的训练速度。此外,A100还支持英伟达自主研发的Tensor Cores加速器,可提供高达20倍的深度学习性能提升。A100广泛应用于各种大规模AI训练和推理场景,包括自然语言处理、计算机视觉和语音识别等领域。
在大模型训练中,V100和A100都是非常强大的GPU。以下是它们的主要区别和优势:
1、架构
V100和A100在架构上有所不同。V100采用Volta架构,而A100则采用全新的Ampere架构。Ampere架构相对于Volta架构进行一些改进,包括更好的能源效率和全新的Tensor Core加速器设计等,这使得A100在某些场景下可能表现出更出色的性能。
2、计算能力
A100配备高达6,912个CUDA核心,比V100的5120个CUDA核心更多。这意味着A100可以提供更高的每秒浮点运算数(FLOPS)和更大的吞吐量,从而在处理大型模型和数据集时提供更快的训练速度。
3、存储带宽
V100的内存带宽约为900 GB/s,而A100的内存带宽达到了更高的1555 GB/s。高速内存带宽可以降低数据传输瓶颈,提高训练效率,因此A100在处理大型数据集时可能表现更出色。
4、存储容量
V100最高可拥有32GB的HBM2显存,而A100最高可拥有80GB的HBM2显存。由于大模型通常需要更多内存来存储参数和梯度,A100的更大内存容量可以提供更好的性能。
5、通信性能
A100支持第三代NVLink技术,实现高速的GPU到GPU通信,加快大模型训练的速度。此外,A100还引入Multi-Instance GPU (MIG)功能,可以将单个GPU划分为多个相互独立的实例,进一步提高资源利用率和性能。
总的来说,A100在处理大型模型和数据集时可能比V100表现更优秀,但是在实际应用中,需要结合具体场景和需求来选择合适的GPU。
二、中国各大厂商如何实现战略式布局
全球范围内,英伟达GPU的竞争非常激烈。然而,海外巨头在GPU采购方面比较早,并且采购量更大,近年来的投资也相对连续。中国的大型公司对于GPU的需求和投资动作比海外巨头更为急迫。以百度为例,今年向英伟达下单的GPU订单数量高达上万块。尽管百度的规模要小得多,去年的营收仅为1236亿元人民币,相当于Google的6%。然而,这显示出中国大公司在GPU领域的迅速发展和巨大需求。
据了解,字节、腾讯、阿里和百度是中国投入最多的AI和云计算科技公司。在过去,它们累计拥有上万块A100 GPU。其中,字节拥有的A100数量最多。不计算今年的新增订单,字节拥有接近10万块A100和前代产品V100。成长期的公司商汤也宣称,其“AI大装置”计算集群中已经部署了2.7万块GPU,其中包括1万块A100。即使是看似与AI无关的量化投资公司幻方,也购买1万块A100。
从总数来看,这些GPU似乎足够供各公司训练大型模型使用。根据英伟达官方网站的案例,OpenAI在训练具有1750亿参数的GPT-3时使用了1万块V100,但训练时间未公开。根据英伟达的估算,如果使用A100来训练GPT-3,需要1024块A100进行一个月的训练,而A100相比V100性能提升4.3倍。
中国的大型公司过去采购的大量GPU主要用于支撑现有业务或在云计算平台上销售,不能自由地用于开发大模型或满足客户对大模型的需求。这也解释了中国AI从业者对计算资源估算存在巨大差异。清华智能产业研究院院长张亚勤在4月底参加清华论坛时表示:“如果将中国的算力加起来,相当于50万块A100,可以轻松训练五个模型。”
AI公司旷视科技的CEO印奇在接受《财新》采访时表示,中国目前可用于大型模型训练的A100总数只有约4万块。这反映了中国和外国大型公司在计算资源方面的数量级差距,包括芯片、服务器和数据中心等固定资产投资。最早开始测试ChatGPT类产品的百度,在过去几年的年度资本开支在8亿到20亿美元之间,阿里在60亿到80亿美元之间,腾讯在70亿到110亿美元之间。
与此同时,亚马逊、Meta、Google和微软这四家美国科技公司的自建数据中心的年度资本开支最低也超过150亿美元。在过去三年的疫情期间,海外公司的资本开支持续增长。亚马逊去年的资本开支已达到580亿美元,Meta和Google分别为314亿美元,微软接近240亿美元。而中国公司的投资在2021年后开始收缩。腾讯和百度去年的资本开支同比下降超过25%。
中国公司若想长期投入大模型并赚取更多利润,需要持续增加GPU资源。就像OpenAI一样,他们面临着GPU不足的挑战。OpenAI的CEO Sam Altman在与开发者交流时表示,由于GPU不够,他们的API服务不够稳定,速度也不够快。
在获得更多GPU之前,GPT-4的多模态能力无法满足每个用户的需求。同样,微软也面临类似的问题。微软与OpenAI合作密切,他们的新版Bing回答速度变慢,原因是GPU供应跟不上用户增长的速度。
微软Office 365 Copilot嵌入了大型模型的能力,目前还没有大规模开放,只有600多家企业在试用。考虑到全球近3亿的Office 365用户数量,中国大公司如果想利用大型模型创造更多服务,并支持其他客户在云上进行更多大型模型的训练,就需要提前储备更多的GPU资源。
三、蓝海大脑大模型训练解决方案
蓝海大脑高性能大模型训练平台利用工作流体作为中间热量传输的媒介,将热量由热区传递到远处再进行冷却。支持多种硬件加速器,包括CPU、GPU、FPGA和AI等,能够满足大规模数据处理和复杂计算任务的需求。采用分布式计算架构,高效地处理大规模数据和复杂计算任务,为深度学习、高性能计算、大模型训练、大型语言模型(LLM)算法的研究和开发提供强大的算力支持。具有高度的灵活性和可扩展性,能够根据不同的应用场景和需求进行定制化配置。可以快速部署和管理各种计算任务,提高了计算资源的利用率和效率。

1、为什么需要大模型?
1)模型效果更优
大模型在各场景上的效果均优于普通模型
2)创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产
3)灵活定制场景
通过举例子的方式,定制大模型海量的应用场景
4)标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求
2、产品特点
1)异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括CPU、GPU等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2)稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3)高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4)全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
3、常用产品配置
1)A800工作站常用配置
CPU:Intel 8358P 2.6G 11.2UFI 48M 32C 240W *2
内存:DDR4 3200 64G *32
数据盘:960G 2.5 SATA 6Gb R SSD *2
硬盘:3.84T 2.5-E4x4R SSD *2
网络:双口10G光纤网卡(含模块)*1
双口25G SFP28无模块光纤网卡(MCX512A-ADAT )*1
GPU:HV HGX A800 8-GPU 8OGB *1
电源:3500W电源模块*4
其他:25G SFP28多模光模块 *2
单端口200G HDR HCA卡(型号:MCX653105A-HDAT) *4
2GB SAS 12Gb 8口 RAID卡 *1
16A电源线缆国标1.8m *4
托轨 *1
主板预留PCIE4.0x16接口 *4
支持2个M.2 *1
原厂质保3年 *1
2)A100工作站常用配置
CPU:Intel Xeon Platinum 8358P_2.60 GHz_32C 64T_230W *2
RAM:64GB DDR4 RDIMM服务器内存 *16
SSD1:480GB 2.5英寸SATA固态硬盘 *1
SSD2:3.84TB 2.5英寸NVMe固态硬盘 *2
GPU:NVIDIA TESLA A100 80G SXM *8
网卡1:100G 双口网卡IB 迈络思 *2
网卡2:25G CX5双口网卡 *1
3)H100工作站常用配置
CPU:英特尔至强Platinum 8468 48C 96T 3.80GHz 105MB 350W *2
内存:动态随机存取存储器64GB DDR5 4800兆赫 *24
存储:固态硬盘3.2TB U.2 PCIe第4代 *4
GPU :Nvidia Vulcan PCIe H100 80GB *8
平台 :HD210 *1
散热 :CPU+GPU液冷一体散热系统 *1
网络 :英伟达IB 400Gb/s单端口适配器 *8
电源:2000W(2+2)冗余高效电源 *1
4)H800工作站常用配置
CPU:Intel Xeon Platinum 8468 Processor,48C64T,105M Cache 2.1GHz,350W *2
内存 :64GB 3200MHz RECC DDR4 DIMM *32
系统硬盘: intel D7-P5620 3.2T NVMe PCle4.0x4 3DTLCU.2 15mm 3DWPD *4
GPU: NVIDIA Tesla H800 -80GB HBM2 *8
GPU网络: NVIDIA 900-9x766-003-SQO PCle 1-Port IB 400 OSFP Gen5 *8
存储网络 :双端口 200GbE IB *1
网卡 :25G网络接口卡 双端口 *1
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com



