在大数据时代,数据分析技术不断演进,从数据仓库到数据湖,再到数据湖仓,企业如何选择合适的数据分析架构?本文将深入探讨数据湖仓(Lakehouse)的概念,以及StarRocks 3.0如何引领这一创新架构,实现数据的高效分析与决策支持。
一、数据仓库的演进与挑战
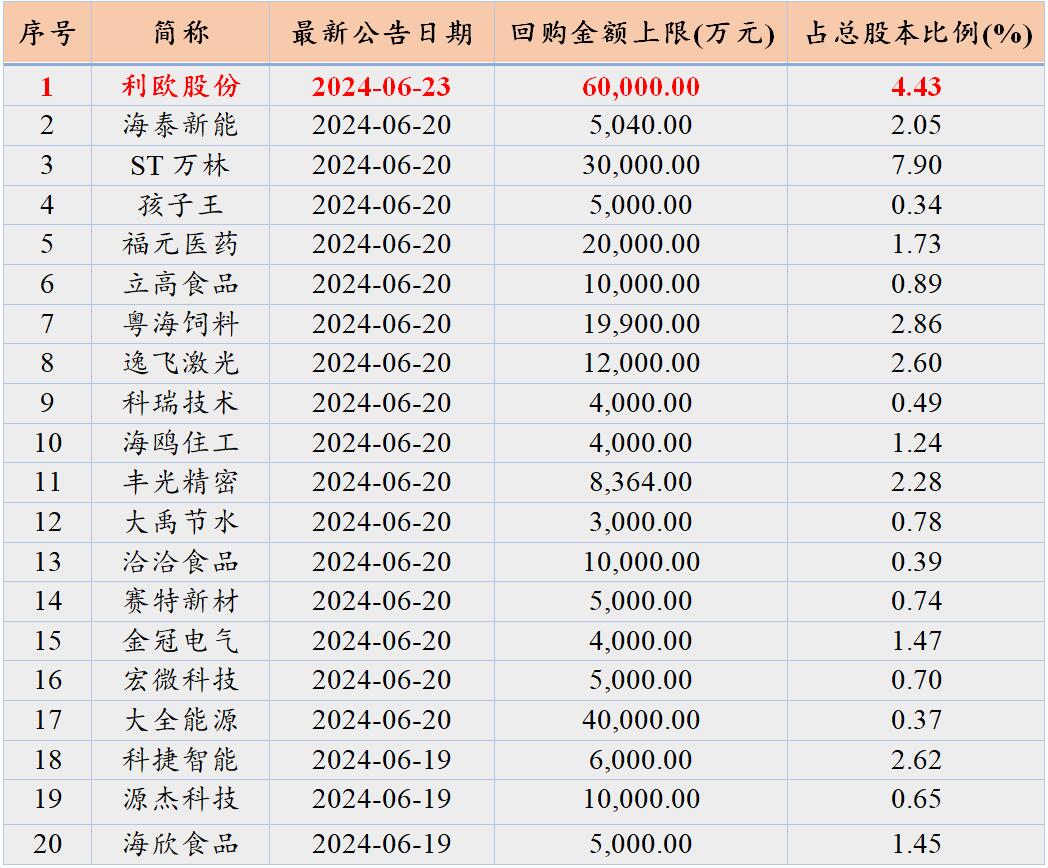
数据仓库自1980年代以来一直是企业数据分析的核心。关系型数据库、日志文件等数据源的数据经过 ETL 处理,统一存储到数据仓库,用于服务 BI 报表、数据挖掘等分析场景。
数据仓库在数据质量、事务处理、查询性能、数据治理等方面有明显的优势,但随着数据分析的需求越来越大,数据仓库的方案也面临一些挑战。
1.数据多样化:除了结构化的数据,半结构化、非结构化的数据越来越多。
2.数据孤岛问题:数据仓库面向主题管理,导致数据分散形成孤岛,难以形成全局统一的数据分析。
3.成本与扩展性:大数据量增长带来数据存储成本与横向扩展的问题。
4.高级数据分析支持:数据仓库能很好的支持 BI 相关应用,但随着 AI 的发展,AI 应用与数据仓库的数据交互效率不高,制约了 AI 应用的发展。
二、数据湖的创新与发展

2010年,数据湖概念的提出为企业提供了一种新的数据存储与分析方式。
如果把数据仓库/集市类比为瓶装水,数据湖则是以更加原生态方式存储数据的大池子。数据湖的核心优势是统一与开放,数据基于对象存储、HDFS 等系统实现低成本、可扩展的 数据存储,并作为企业数据的 Single Source of Truth(SSOT);同时数据的数据格式是开放的,便于不同的应用灵活访问。
数据湖解决了数据成本与扩展性、数据多样性、数据孤岛等问题,并同时满足 BI 与 AI 应用对数据分析的诉求;但数据湖在数据分析性能、数据管理与治理方面仍然存在较大的挑战。
三、湖仓分层架构的融合与应用
业界探索数据仓库与数据湖的融合,湖仓分层架构应运而生。
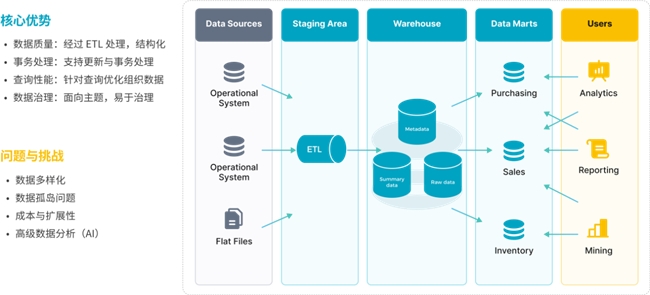
数据仓库与数据湖各有长处,业界持续在探索两者如何更好的融合,在过去几年湖仓分层的架构的到广泛的应用。企业数据统一写到数据湖,作为统一存储,湖上开放的数据可以服务 AI、ML 等应用场景;数据湖上部分数据经过 ETL 处理导入到数据仓库服务 BI 等 OLAP 分析场景。
湖仓分层架构融合了数据湖与数据仓库的优势,但面临一些问题与挑战。部分数据从数据湖导入到数据仓库,数据链路的增长影响数据分析的时效性,两份数据也会带来冗余存储、数据口径不一致的问题;另外,对于数据仓库里加工产生的数据,仍然很难高效的服务 AI 场景。
四、数据湖仓的兴起
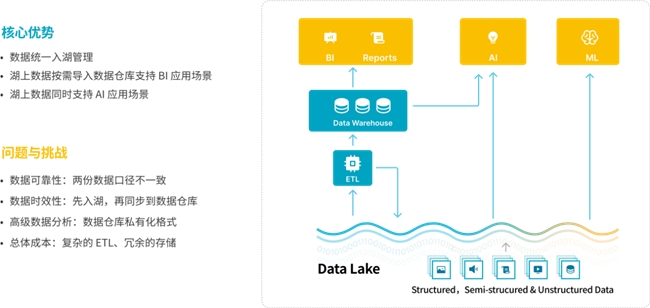
数据湖仓作为新一代数据分析架构,兼具数据仓库与数据湖的优势。
新兴的数据仓库如 Snowflake、Redshift、BigQuery 均采用云原生存算分离架构演进,并且支持直接查询开放数据湖的能力。数据湖在事务支持、查询性能等方面的能力不如数据仓库,近年来随着新兴数据湖格式如 Iceberg、Hudi、Delta Lake 等的发展,事务支持能力得到提升。
另外,在查询性能上,通过不断优化数据湖上的数据分布以及增加缓存机制等技术的演进,数据湖上的数据分析性能已经大幅提升,达到接近数据仓库的水平。
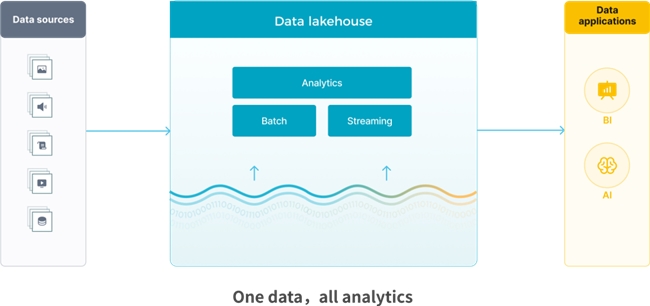
从数据湖和数据仓库的演进来看,两者在不断的融合,并逐步往数据湖仓的方向演进,兼具数据湖与数据仓库的优势。数据湖仓作为一种新的数据分析架构,用户采用湖仓就能方便将数据源和数据应用连接在一起。
数据湖仓兼具数据仓库与数据湖的优势,湖仓具备开放统一的数据存储能力,并基于统一存储直接服务批处理、流处理、交互式分析等多种分析场景,实现湖仓 One data,all analytics 的业务价值。
五、StarRocks 3.0:湖仓技术创新
StarRocks 2.0 版本凭借其优异的查询性能在业界得到广泛应用,很多用户采用湖仓分层架构,并将 Hive、Iceberg 等数据湖里的数据部分导入到 StarRocks 服务 OLAP 分析场景。
StarRocks 3.0的存算分离架构、极速湖仓分析和物化视图技术,为用户提供了高效、灵活的数据分析解决方案。
特性1:存算分离架构
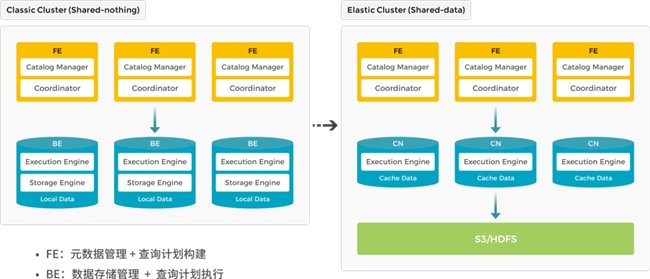
StarRocks 存算分离 2023年4月正式发布,目前已有上百家用户上线存算分离架构。与存算一体架构相比,保持了原有简洁的架构;同时极大的降低数据存储成本,提升计算的弹性能力。
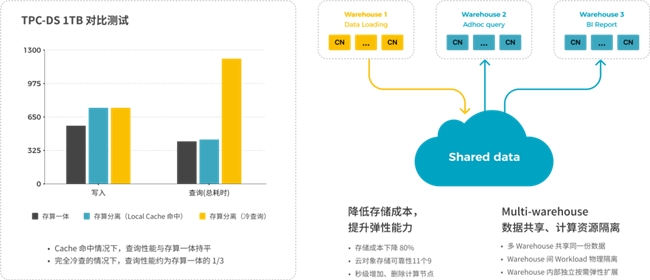
访问远端对象存储的延时相比本地存储有数量级的提升,StarRocks 通过 Data Cache 机制提升数据访问性能,确保热数据与存算一体架构接近。根据实际测试,存算分离缓存命中的情况与存算一体架构相比性能完全相同;在完全冷查询时,性能大概是存算一体的30-50%。
在存算分离架构下,StarRocks 可以方便的支持 Multi-warehouse 的能力;多个 Warehouse 共享一份数据,不同 Warehouse 应用在不同的 Workload,计算资源可以进行物理隔离,并且可以按需独立弹性伸缩。
特性2:极速湖仓分析
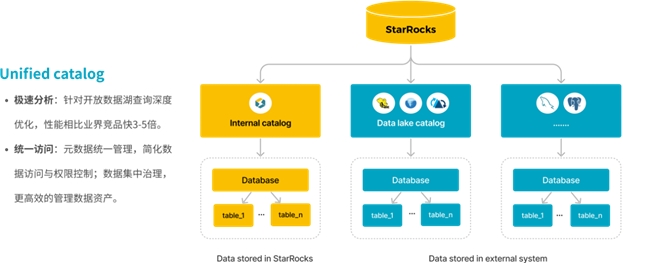
StarRocks 3.0 提供统一 Catalog 管理的能力,用户不仅能高效分析导入到 StarRocks 的数据,同时也支持直接分析开放数据湖 Apache Hive、Apache Iceberg、Apache Hudi、Apache Paimon 的数据,分析性能相比业界同类产品快3-5倍。
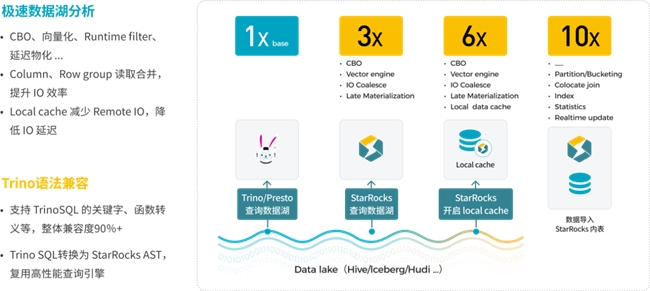
StarRocks 在查询层 CBO、向量化、Runtime filter 等技术可以无缝应用到开放数据湖分析,但湖上数据分析还面临一些其他挑战。湖上数据一般以原始格式存储,数据组织上没有针对查询优化,同时访问远端对象存储/HDFS 的延时相比本地盘更高。StarRocks 通过 I/O 合并、延迟物化、Data cache 等一系列关键技术加速湖上数据分析。另外,为了让用户平滑的获得 StarRocks 极速湖仓分析性能,StarRocks 实现了 Trino 方言的兼容,用户可以采用 StarRocks 无缝直替 Trino。
特性3:物化视图
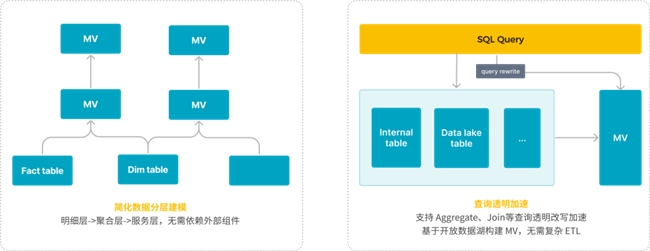
StarRocks 物化视图提供了一种从预建模到后建模的方法,缩短业务建模以及上线时间。业务可以直接查询原始数据,借助 StarRocks 极致的查询性能,已经能满足绝大部分场景的需求;如果直接查询性能不满足,则可以按需构建物化视图来加速查询,StarRocks 支持物化视图的透明查询改写,实现业务无感的情况下实现查询加速。
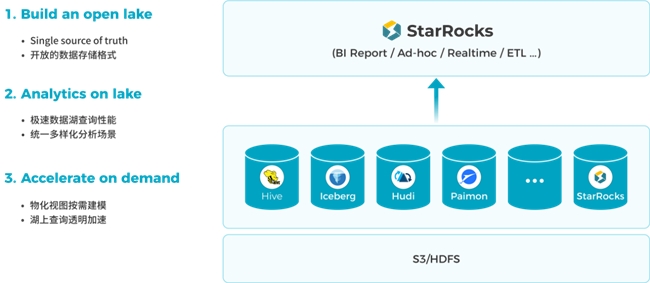
湖仓应用:基于 StarRocks 构建 Lakehouse
基于 StarRocks,用户可以高效的构建 Lakehouse 数据分析架构,用户可以选择 StarRocks 内表或开放数据湖 Apache Iceberg、Apache Hudi、Apache Paimon 做为统一的数据存储,基于 StarRocks 服务BI报表、Ad-hoc 等多样化的分析场景,对于业务性能要求高的查询,通过物化视图技术实现按需透明加速。
六、互联网用户的湖仓最佳实践案例
本段落分析了腾讯微信、携程旅行等企业如何利用StarRocks实现数据的准实时分析和查询性能的显著提升。
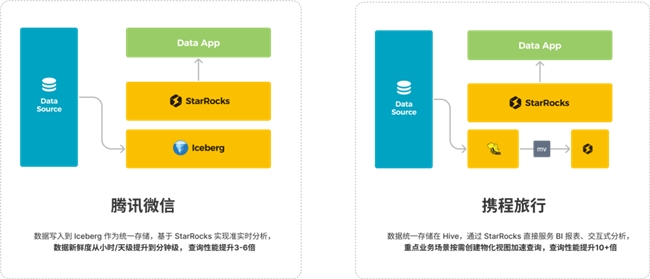
1.腾讯微信:数据写入到 Iceberg,基于StarRocks实现准实时分析,数据新鲜度从小时/天到分钟即,查询性能提升3-6倍。
2.携程旅行:数据统一存储在Hive,通过 StarRocks直接服务BI报表,交互式分析。重点业务场景按需创建物化视图查询加速,查询性能提升10+倍
结语
Lakehouse 兼具数据仓库与数据湖的优势,是下一代数据分析架构的演进趋势;StarRocks 是构建 Lakehouse 的最佳选择,已在微信、小红书、携程、平安银行等数十个大型企业落地实践,帮助企业实现 One data、all analytics 的业务价值。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:182 3641 3660 投诉邮箱:7983347 16@qq.com