在大数据时代,湖仓一体架构(Lakehouse)因其统一且高效的数据处理与分析能力备受关注。
StarRocks 作为一款强大的查询引擎,当前已已无缝集成多种数据湖组件,如 Apache Iceberg、Apache Hudi、Delta Lake、Apache Paimon 等,实现了对数据湖的实时查询与分析。不仅能够作为查询引擎直接读取数据湖中的数据,还支持物化视图等高级功能,进一步提升查询性能,帮助企业“一键实现”湖仓架构。
StarRocks与Apache Iceberg的集成
Apache Iceberg 是一个开源的表格式,用于在大数据平台上提供高效、可扩展的数据存储。目前,用户可以直接在 StarRocks 中查询存储在 Iceberg 中的大规模数据集,无需数据迁移或转换。
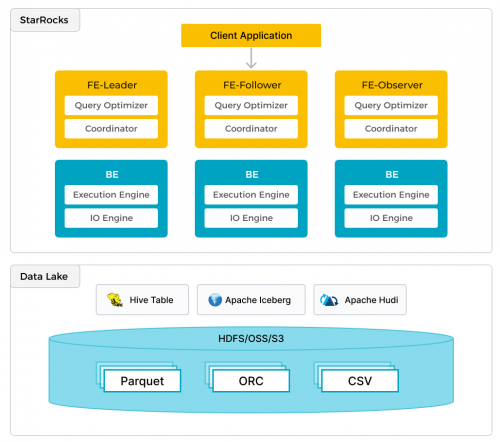
这一集成不仅简化了数据处理流程,还显著提升了查询效率。StarRocks 支持 Iceberg 表的 Snapshot 查询,能够获取数据的最新状态,满足用户对实时数据分析的需求。
实战案例:微信如何利用StarRocks实现湖仓一体,重塑数据平台
微信在数据平台建设过程中,面临数据体验割裂和存储冗余的痛点。其Hadoop架构存在查询慢、数据延迟高、架构臃肿等问题。尽管后续升级到基于ClickHouse的亚秒级实时数仓,解决了海量数据和极速查询的挑战,但尚未实现计算侧和存储侧的统一。此外,海量数据规模、极高的查询耗时要求以及数据时效性的需求,也对现有系统提出了严峻挑战。
基于 StarRocks 的解决方案:
微信通过引入StarRocks的湖仓一体方案,实现了数据平台的统一。采用湖上建仓和仓湖融合两种技术路线,分别应对离线分析和实时分析场景。
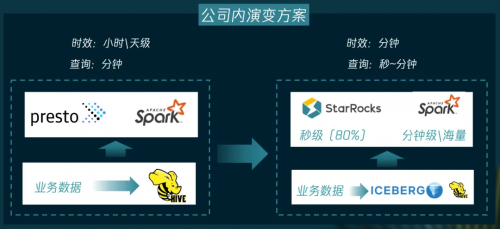
湖上建仓通过StarRocks替代Presto,提升查询效率并降低成本;仓湖融合则通过跨源融合联邦查询和冷存下沉,实现实时性和数据统一。同时,开发了实时增量物化视图技术,支持大规模数据的实时更新和高效查询。
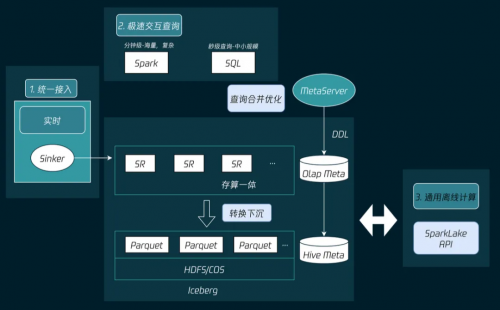
实施湖仓一体方案后,微信在多个业务场景中取得了显著收益。以直播业务为例,运维任务数减半,存储成本降低65%以上,离线任务产出时间缩短两小时。整体上,集群规模扩大至数百台机器,数据接入量近千亿,显著提升了数据分析的效率和实时性。未来,微信将继续探索和完善湖仓一体架构,实现面向SQL的统一查询体验、接入/查询体验统一、存储统一及秒级/分钟级延迟架构体验统一,进一步提升数据分析的效能和价值。
2. StarRocks 与 Apache Hudi 的集成
Apache Hudi方面,StarRocks 提供对 Hudi 表的高效查询能力,通过全新 Connector 框架,实现了对 Hudi 表的 Snapshot 查询、Incremental 查询和 Read Optimized 查询的支持。特别是 StarRocks 2.4 及更高版本,通过简化配置过程,用户可以更便捷地查询数据库下所有 Hudi 表格式的数据。
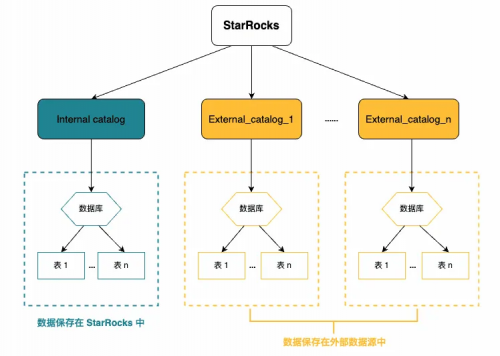
3. StarRocks 与 Delta Lake 集成与应用
Delta Lake 是另一种流行的数据湖格式,专注于提供 ACID 事务和可靠的批处理。StarRocks 支持查询 Delta Lake 中的 Parquet 格式数据,支持多种压缩格式(如 SNAPPY、LZ4、ZSTD、GZIP 和 NO_COMPRESSION)。
用户可以通过创建 Delta Lake Catalog 来访问 Delta Lake 中的数据。StarRocks 支持查询 Delta Lake 中的表。
4. StarRocks 与 Paimon 的集成
Apache Paimon 是一种新一代的湖格式,支持高效实时更新和统一的批处理与流处理操作。StarRocks 通过 External Catalog 功能支持直接查询存储在 Paimon 数据湖中的数据,并执行 SQL 查询,实现数据的快速检索。StarRocks 支持多种查询优化策略,包括 Data Cache 和异步物化视图,可以显著提升查询性能。

StarRocks与Paimon的集成应用已经在多个生产环境中得到验证。在测试中,StarRocks查询Paimon数据的效率是Trino的4.3倍,开启Data Cache后,查询性能更是提升了35.4%。这表明StarRocks与Paimon的集成应用可以显著提升数据湖中的实时数据分析能力。
行业标杆:汽车之家采用StarRocks+Paimon,打造极速批流一体湖仓分析
汽车之家在数据仓库建设中,面临实时与离线数据分别处理导致的技术栈复杂、数据新鲜度不一及查询效率低下等痛点。离线数仓使用Hive,数据延迟较高;实时数仓依赖Flink、Kafka等技术,但在处理复杂SQL时资源消耗大,开发周期长。尽管尝试使用Iceberg作为统一存储方案,但发现其在流式处理上的功能不足。
StarRocks+Paimon解决方案:汽车之家选择Apache Paimon作为新的数据湖解决方案,结合Flink实现流批一体处理。Paimon的简洁健壮架构、增量且有序的数据读取、部分更新等能力,满足了流式湖仓的需求。通过Paimon存储实时与离线数据,降低了开发和维护难度,提高了数据新鲜度。同时,利用StarRocks的物化视图和Sort Compaction功能优化查询效率,减少资源消耗。
实施解决方案后,汽车之家在新用户转化分析、流量日志入湖及资源入湖等场景中取得了显著成效。新用户转化分析的宽表时效性从天级提升到分钟级,开发效率提升5倍以上,资源使用节省60%。流量日志清洗SLA提升1小时,查询效率显著提升。资源数据新鲜度提升至分钟级,下游业务方平滑过渡,无需大量开发调整。此外,Paimon的优化实践如支持代理用户、优化写入任务内存占用等,进一步提升了系统的稳定性和性能。
使用 Paimon + StarRocks 极速批流一体湖仓分析
StarRocks+Paimon的湖仓分析方案支持多种场景,包括Trino兼容、联邦分析、透明加速、数据建模和冷热融合。
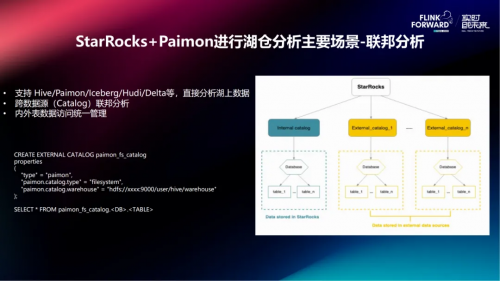
原有Trino作业无需修改即可在StarRocks上运行;联邦分析允许不同数据源之间的联合查询;透明加速通过物化视图优化查询性能;数据建模支持多层嵌套物化视图,便于数据体系构建;冷热融合则通过TTL机制优化存储成本和查询效率。JNI Connector作为关键技术,实现了C++与Java数据源之间的高效交互。
性能测试:在EMR环境下,通过对比测试StarRocks与Trino在TPCH 100G数据集上的性能,结果显示StarRocks的查询性能是Trino的15倍,验证了StarRocks+Paimon方案的高效性。
镜舟科技作为基于 StarRocks 开源项目的商业化公司,深入参与 StarRocks 社区推广和技术贡献,致力于推动湖仓一体的最佳实践应用于各行各业。未来,镜舟科技将积极与数据湖领域的其他优秀厂商和开源项目开展合作,共同构建更加完善的湖仓一体生态。
复制成功
返回
顶部
0.247882s
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:157 3889 8464 投诉邮箱:7983347 16@qq.com



