4月26日,科大讯飞旗下讯飞星火大模型V3.5(以下简称“讯飞星火V3.5”)春季上新,不仅发布业界首个长文本、长图文、长语音大模型,还进一步升级星火语音大模型,首发多情感超拟人合成,具备情绪表达能力,并推出一句话声音复刻功能,让科技更有温度。
早在今年 1 月,科大讯飞首发了超拟人合成语音功能,让 AI 不再是冷冰冰的播音腔,同时具备超强的情绪感知能力,能像“知冷知热”的朋友一样带入情感互动,更具人情味。这一技术的提升背后不仅得益于讯飞星火V3.5在语义理解、指令跟随和多轮对话的演示中展现的优异能力,还有在情绪感知和拟人合成方面的出色表现。

讯飞星火 V3.5 此次的更新版本中,这一功能再度加强,首发多情感超拟人合成功能,进一步提升了合成声音中情绪表达感知能力,情绪可感知度达到 85%以上,可以实现包括高兴、抱歉、安慰、撒娇、困惑等多种情感语气表达。正如刘庆峰说,“技术在不断的进步,我们希望在安全可控的前提下,能够带来这个社会更有温度的人工智能的体验,能够真的帮助到那些特别需要帮助的人。今天这个世界更需要有温度的科技。”
不仅能用,还要好用、易用,这或许才是部分大模型应用在同质化竞争中脱颖而出的关键因素。科技不是冷冰冰的存在,AI 时代的科技更要能力与温度兼顾,方能收获大众的欢迎。
长文本已经成为国产大模型比拼的新方向。在经过长达一年的对标 ChatGPT-4、比拼参数大小的同质化竞争之后,中国人工智能公司们终于找出了一个更容易被普通用户理解、也更能直观地超越美国同行们的差异化标的。掀起这一波竞争浪潮的是国内大模型创业公司月之暗面。这家公司在去年将旗下的大模型 Kimi 的上下文参数规模提升至 20 万字,上个月又提升至 200万字,迅速引爆市场。3月,阿里旗下的通义千问已经将这一数字更新到 1000万字,宣称是“全球文档处理容量第一的 AI 应用”。华泰证券在一份研报中指出,具有长上下文的大模型通用性更强,用户将特定领域的知识通过上下文的方式输入到模型中,模型即可通过上下文学习掌握相应内容,一定程度上代替模型的微调。但经过几个月的比拼跟进之后,长文本之于大模型似乎又成了一项厂家炫技的同质化环节,以至于有媒体已经飞快地喊出了“长文本降温”的口号,长文本如何才能真正落地陷入瓶颈。
大模型长文本功能的落地需要重点解决两个问题。一是海量文本的高效处理。面对上百万甚至上千万文字,模型后台消耗的运算资源也成倍增加,业界的一些大模型往往智能处理前 20% 或前 50% 的内容,之后的处理效率就减慢。二是如何保证大模型在科研、医疗、法律等行业专业场景的准确率,这样才能解决大模型在刚需场景的应用问题。科大讯飞董事长刘庆峰介绍,为了解决大模型应用效率和准确率问题,讯飞星火 V3.5 提升了对长文本的理解、学习、回答能力,并进行了重要的模型剪枝和蒸馏,从而推出业界最优的 130亿参数的大模型。在效果损失仅 3% 以内的情况下,使得星火在文档上传解析处理、知识问答的首响时间以及文字生成效率方面都获得了极大的效率提升。在对比测试中,使用讯飞星火对比国内可测最好的大模型,在保障长文本效果的情况下,无论是10K、64K、128K token,还是更长的文本上,星火大模型的性能都是业界最优。
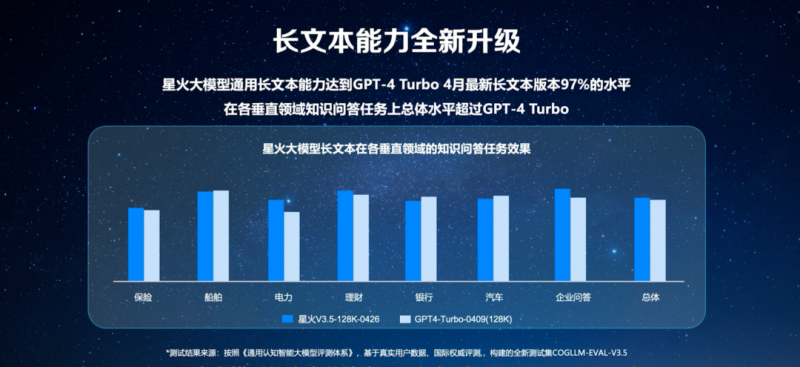
解决了效率和准确率的问题,长文本才不至于只停留在参数比拼的噱头上,真正落地于应用场景。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
文章投诉热线:182 3641 3660 投诉邮箱:7983347 16@qq.com