SequoiaDB从「多模数据湖」、「实时数据湖」发展到「湖仓一体」架构,为客户提供「数据核心」所需的全量数据存储,实时对客服务,及基于统一数据源的分析能力,充分激活客户的离线数据。当中,数据入湖的时效性直接影响整体数据应用效果,巨杉数据库通过对接业界主流的Flink,Spark和Storm等主流的流式框架,实现实时生产数据的高速入湖,原汁原味的将数据保留在巨杉数据库中。SequoiaDB是巨杉数据库通过10年的不断迭代,从多模数据湖架构演进出来的“湖仓一体”架构产品。SequoiaDB的“湖仓一体”结合了数据湖与数据仓库,是一个融合的基础设施环境,支持从原始数据到精炼数据的整个过程,并最终提供优化后的数据以供消费。
秒级数据入湖
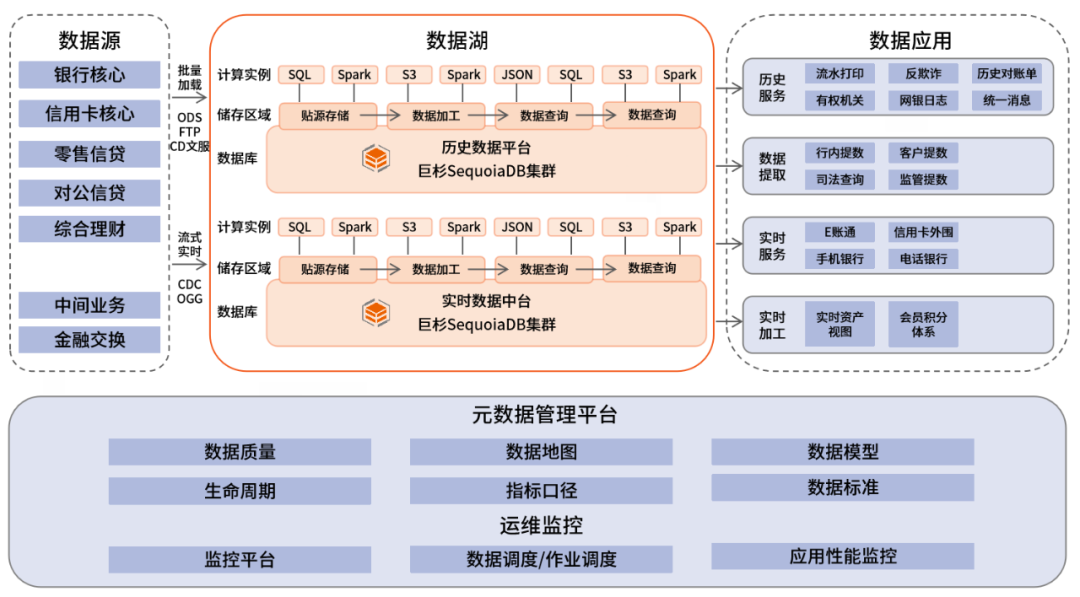
从客户的结构化数据需求出发,巨杉众多的金融客户着眼于盘活海量的历史存量数据,并同时卸载发生在传统Oracle/DB2上的业务。因此,巨杉依托自研的SequoiaDB分布式数据库,形成了历史数据平台的方案。从业务的角度出发,SequoiaDB通过高性能的连接器,对接包括Flink,Spark和Storm等主流的流式框架,实现实时生产数据的高速入湖,原汁原味的将数据保留在巨杉数据库中。这里起到的作用有点像数仓模型中的ODS层,但巨杉又利用其分布式数据库高并发访问的能力,可以直接对外提供实时数据访问服务。
鉴于SequoiaDB多副本高可用的特性,很多用户实际上把巨杉数据库作为全系统数据的全量最终存储。在部署实践里,前端操作型数据库产生的数据变更在通过ogg/CDC等工具抽取后,通过批量的方式load到巨杉数据库中;或是加载到以kafka为代表的各类消息队列,再通过流式引擎写入巨杉数据库中。流式和批量数据汇总加工整合即可对外提供服务,根据业务需要,实时入湖的数据从业务实际发生到在巨杉中提供访问服务时延在秒级。
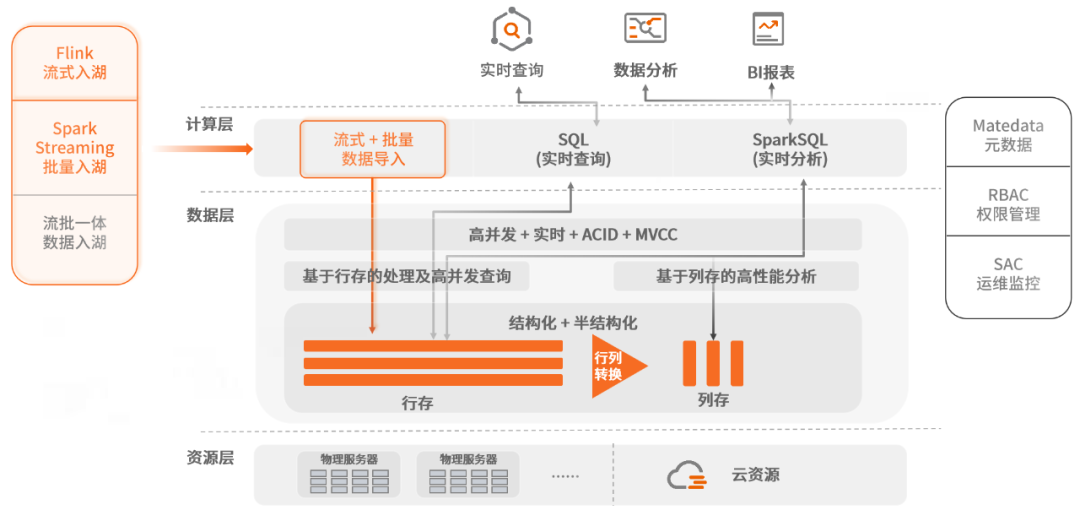
上图有两个核心技术点需要关注。一是数据入库链路,从架构中可以很清晰的看到通过流和批两条数据链路,这是当前比较成熟的一个典型的Lambda架构。为了尽可能的高效接收来自不同数据源的数据,SequoiaDB开发了Spark connector和Flink connector等多种通用数据格式的解析器,打通实现了高可靠的数据链路,支持增删改各类操作,并在客户场景中解决exactly once数据入库问题。
其次是随着巨杉数据库在业务系统的深入,很多用户发现把数据从取出,做ETL,加载到DW层再做完各类统计分析汇总时,会存在以下问题:
1.时延较高,无法满足实时分析的需求
2.搬迁复制数据成本高,数据要在不同条件下保存多份,还要开发大量的工具
3.传统数仓模型不能很好的适应业务变更,需要的专业技能门槛也很高
所以部分客户开始跟巨杉一起探讨直接在海量数据湖上做数据转换和分析的可能,也就形成了现在巨杉数据库的“湖仓一体”架构。
流式数据加工
针对客户提出的流式数据加工处理,以及未来越来越多的实时分析场景,SequoiaDB在结合Spark Streaming和对接Flink后,提供简单易用的数据加载工具和列存的数据加载功能。SequoiaDB还开发了行存数据到列存数据的自动化转换工具,客户只需要基于需求简单配置需要转换分析的表,就可以实现实时增量数据同步转换,极大的方便简化数据加工师和分析师的工作。总的来说,客户可以在一个SequoiaDB平台实现低延时的数据入库,高并发的即时数据查询,几乎透明的行列数据转换,以及高性能的数据加工分析能力。
结语
SequoiaDB通过对接业界主流的流式框架,实现了多源数据的快速入湖。未来,巨杉数据库将继续不断创新,打造更加安全、稳定、可靠的数据库系统,持续助力金融行业客户信息化创新,释放全量数据价值。
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com



