

近日,云知声正式推出UnisoundU1-OCR文档智能基础大模型。作为业内首个工业级文档智能基座,该模型凭借性能SOTA、可信可验、开箱即用、高效部署、强适配五大核心优势,实现从“字符感知”到“文档认知”的跨越,正式开启OCR3.0时代,为文档智能处理树立全新行业标杆。
文档智能历经三代技术演进:OCR1.0仅能识别文字,OCR2.0实现端到端版面理解,而UnisoundU1-OCR突破边界,在版面理解基础上深度洞察语义,可自动完成文档分类与业务级信息抽取,完成从“认字”到“懂文档”的质变。
该模型采用ViT+LLM架构,视觉编码器搭载NaViT架构,支持文档分辨率动态处理,3B参数规模兼顾效率与语义理解能力。其首创“语义驱动+动态聚焦”策略,先梳理文档结构再提取内容,构建“语义地图”精准识别层级关系;强化空间对齐模块,精准还原表格、图文混排结构;运用Multi-TokenPrediction技术与全任务强化学习,推理效率提升80%以上,有效遏制定位幻觉。
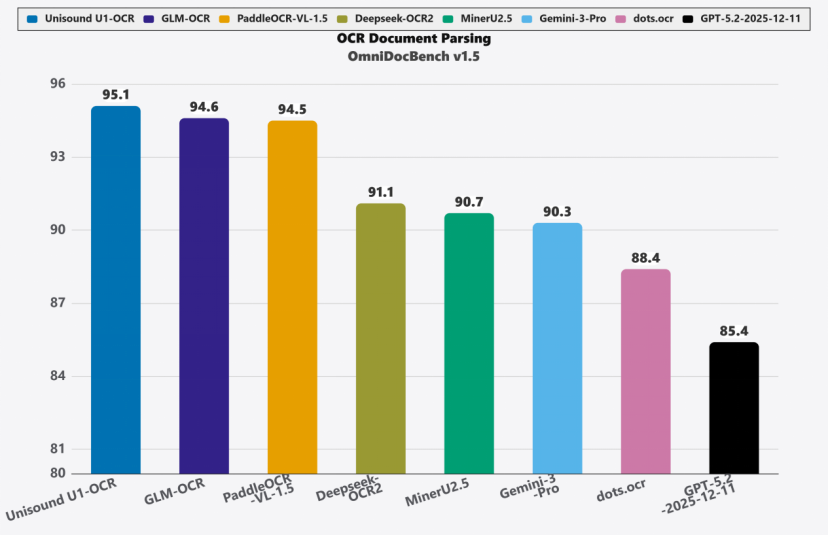
凭借技术创新,UnisoundU1-OCR在多项权威评测中稳居全球第一梯队:OmniDocBenchV1.5评测以95.1分斩获SOTA,超越GLM-OCR、Gemini-3-Pro等模型;D4LA评测F1分数达90.8,大幅领先同类方案;DocLayNet评测F1分数95.9,表格识别、微小文本检测优势突出;内部业务测试中,医疗、文书等场景信息抽取能力超越多款主流大模型。
立足工业级落地需求,模型打造四大核心能力,实现从“读懂”到“执行”的突破。可信可查方面,独创“坐标-文本-语义”融合架构,像素级定位溯源,审核秒级完成;业务融合上,深度整合医疗、金融行业知识,50余种常见文书分类准确率超99%;高效部署支持私有化与离线运行,数秒完成十多页文档处理;超强适配可应对拍照模糊、水印干扰、复杂排版等极端场景,摆脱对标准化文档的依赖。
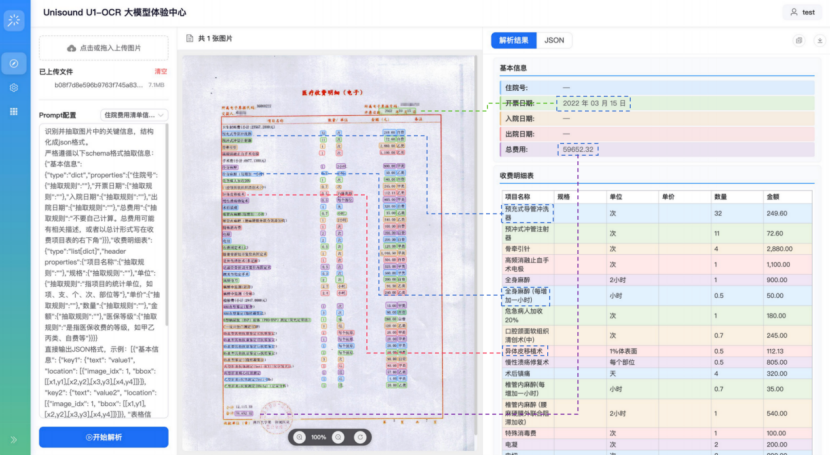
在实际场景中,U1-OCR可自动对齐医疗费用清单字段、分割混叠病历单据、净化水印文档、解析嵌套表格,输出结果直接可用。以医疗费用使用场景为例,模型能够深度理解业务需求,实现数据的“即抽即用”。医疗费用清单抽取中,模型能自动理解语义,兼容不同医院的写法差异,并根据业务字段抽取规则精准剔除无关的大类干扰项,实现结果直接入库。同时,模型支持像素级的坐标回溯,通过不同颜色将抽取结果与原图位置一一对应,这种透明的可信体系让传统的“全文重读”进化为“秒级定点确认”,在保障数据入库准度的同时,实现了业务效率的质变。
Unisound U1-OCR开启OCR 3.0时代,标志着AI从单纯“识字”跃迁至“理解业务逻辑”。此次发布不仅是OCR技术的代际革新,更标志着AI从感知走向认知,为政务、医疗、金融等行业数字化转型提供强劲动力。未来,云知声将以文档智能为入口,持续推进AGI技术落地,让每一份文档都成为智能升级的核心载体。





